



















Introduction
If you’re working with maps, you’ve probably already come across the concept of layers. Layers are a key component in Mapbox (as well as any other map provider, such as Google Maps, OpenStreetMap, etc.). In simple terms, layers define how a dataset will be represented on your map. Different datasets will be associated with different layers.
For example, let’s say your map will display information about Roads, Parks and green spaces, and Population Density. Each of these three datasets will be associated with a layer that determines how it is visualized. Roads will likely be represented as Lines, parks could simply be points indicating their location, while population density could be shown using polygons of different colors covering large areas of the map.
Typically, map rendering systems make use of multiple layers, and sooner or later, as a developer integrating a map provider into your application, you will encounter the problem of ordering them. In this article, we will delve into how Mapbox GL JS handles layer ordering and discuss the solution implemented in a project at Qubika.
Why is the order of layers important?
In Mapbox GL JS, the order is important because the data associated with each layer will be rendered on top of others according to the order in which their layers were added to the map. Referring back to the previous example, if the roads are added first and then the population density information, the polygons from the latter could potentially render on top of the road information, making it difficult to visualize the roads.
Basic ordering in Mapbox GL JS
Thus, the loading order matters. In a fully controlled environment, if we are careful, we can ensure the order of the layer stack by explicitly and sequentially adding each one. To add layers to the map, we use the addLayer function:
map.addLayer({id: 'population-density', …})
map.addLayer({id: 'roads', …})In the above code, the road data will be rendered on top of the population density data because it is added afterward.
Alternatively, when adding a new layer, Mapbox GL JS allows you to define where in the stack it will be positioned by supplying a second parameter to the addLayer called beforeId. The parameter beforeId takes the ID of an existing layer to insert the new layer before, resulting in the new layer appearing visually beneath the existing layer. If this argument is not specified (as in the example above), the layer will be appended to the end of the layers array and appear visually above all other layers.
map.addLayer({id: 'roads', …})
map.addLayer({id: 'population-density', …}, 'roads') // note the second param 'roads'Problem
First of all, as you may notice, to add layer A behind layer B, layer B must be added before layer A. This is why, in the previous example, we loaded the roads layer first and then referenced it when adding the population density layer.
Now, the above examples work correctly as long as we can ensure the order of the addLayer invocations. However, in many applications, we may not have complete control over the order in which data is loaded. Imagine that certain layers are added as a result of asynchronous operations tasked with fetching the data from an external API, or that users of the application have the ability to add and remove layers at will. Under these conditions, ensuring a specific order becomes challenging, as we cannot assume which layers are present in the stack to use as references when adding new ones.
Solution 1: Using Slots
Slots act as placeholders within the layer stack, creating well-defined insertion points that developers can reference when adding new layers. This approach allows you to ensure that specific layers are added within designated slots. If a slot is positioned behind another slot, the layers within it will be rendered behind the layers of the latter.
Let’s assume that the style we are using contains three slots: bottom, middle, and top.
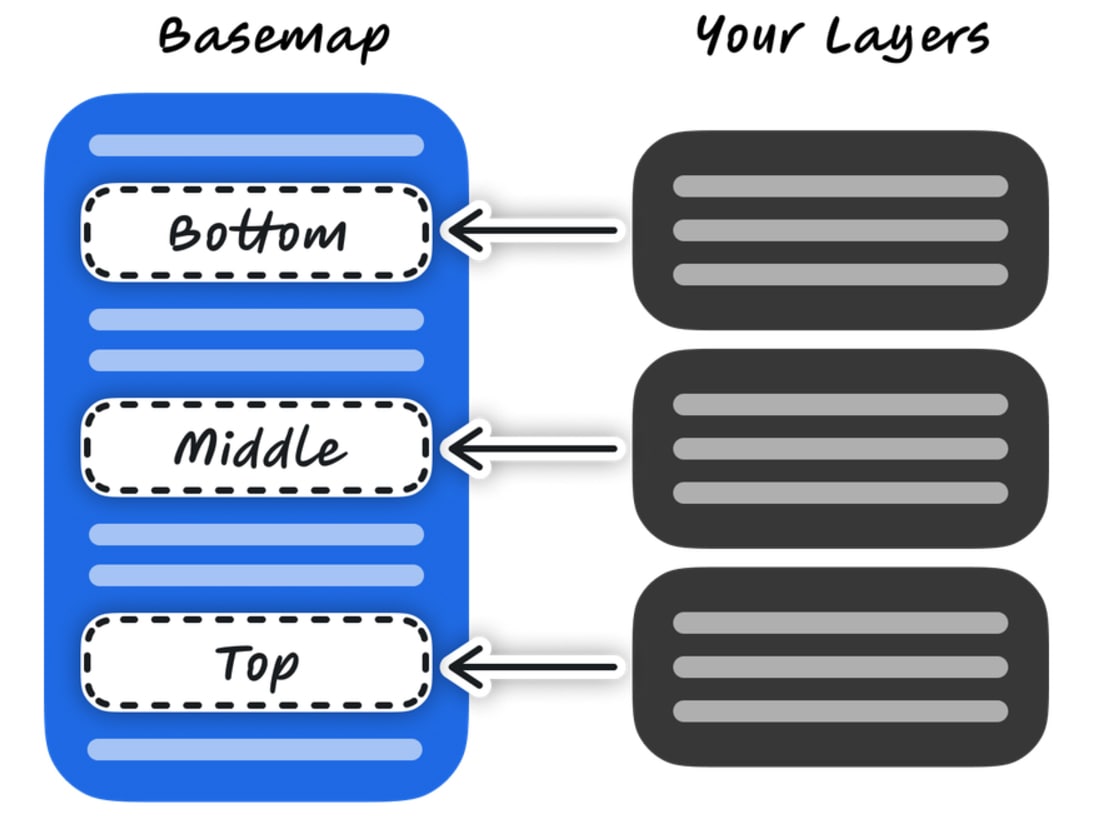
Referring back to our example, if we wanted to ensure that the roads layer is rendered above the population density layer, we could assign them to certain slots by using the slot property as follows.
map.addLayer({id: 'population-density', slot: 'middle', …})
map.addLayer({id: 'roads', slot: 'top', …})
Thus, slots seem to resolve the issue, but they come with some disadvantages. The first is that we cannot ensure the order within the slot. Therefore, we would need as many slots as layers we want to sort. The second disadvantage is that slots of a predefined style are not customizable. To define your own slots, it is necessary to create your own style. This could be done, for example, using Mapbox Studio, but creating your own style just to have the necessary slots is a significant overkill.
Solution 2: Creating the ZLayers module
Mapbox GL JS does not offer another mechanism for ordering layers beyond the beforeId parameter and the slots. It is under these conditions that we decided to implement a simple module to help us ensure the correct order whenever a new layer is added.
The idea is to begin by adding empty layers that we will use as references for adding other layers. We will call these reference layers z-layers, as they will provide an order on the z-axis. The z-layers will define the position of the layers containing actual data in our application at all times. We can think of them as placeholders that maintain the positions of the other layers, similar to slots. The z-layers will be referenced using the beforeId parameter.
So, let’s start by defining an object (it could also be a class) that contains an ordered array with all the ids of the layers our application will use. The closer to the beginning of the array, the lower in the stack the layer will be rendered:
const ZLayers = {
LAYER_ORDER: [
'population-density',
'roads',
'parks'
],
}
export default ZLayers
Now let’s define a load function, which will be responsible for adding the z-layers to the map:
const ZLayers = {
LAYER_ORDER: [...],
load: function(map) {
map.addSource('empty', {
type: 'geojson',
data: { type: 'FeatureCollection', features: [] }
})
for (let i = this.LAYER_ORDER.length - 1; i >= 0; i--) {
this.map.addLayer({
id: `z-${i}`,
type: 'symbol',
source: 'empty'
}, (i == this.LAYER_ORDER.length - 1) ? undefined : `z-${i+1}`)
}
}
}
Let’s break it down. First, a source with the identifier empty is added, which is actually empty as you can see by the empty array assigned to the data.features property. This is done because every layer must always be associated with a source, so we’ll use this dummy source for that.
Next, we have a for loop that goes through the layer ids from the last element, which will be rendered on top of all the others parks, down to the first element, which is going to be the bottom layer population-density. In each iteration, a z-layer with an id formatted as z-[index] is added just behind the layer added in the previous iteration (this is achieved by dynamically calculating the second parameter beforeId). The function load will be called as soon as the map is initialized:
map.on(‘load’, () => {
ZLayers.load(map)
})
Once executed, we will have added the following layers to the layer stack:
z-0
z-1
z-2
Finally, we will add one last function to ZLayers. This function will receive the id of a layer from our app, and it will return the id of the associated z-layer. This will help us obtain the beforeId value when adding layers.
const ZLayers = {
LAYER_ORDER: [...],
load: function(map) { ... },
myPosition: function(layerId) {
if (!this.LAYER_ORDER.includes(layerId)) { throw new Error(`Layer ${layerId} not included as a sortable layer`) }
return `z-${this.LAYER_ORDER.indexOf(layerId)}`
}
}
Now, it will just be a matter of adding the data layers in the following way:
map.addLayer({id: 'population-density', …}, ZLayers.myPosition('population-density'))
map.addLayer({id: 'roads', …}, ZLayers.myPosition('roads'))
And that’s it! You don’t have to worry about which addLayer invocation comes first; it no longer matters if the layers are added as a result of asynchronous operations, nor does it matter if users of the app can remove and add new layers. The order will always be well-defined.
Bonus
Typically, the styles you use for your map will contain at least one layer that is rendered as a background. In this case, that layer will always be rendered below the others. Let’s suppose that in our example there is such a layer with the id background. After adding the z-layers, the stack would look as follows (you can quickly check the stack by calling map.getStyle().layers)
background
z-0
z-1
z-2
If you also need to work with this type of layer, for example, if users are allowed to change the map style, consequently modifying the background layer, you would just need to place the id of this layer at the beginning of the ZLayers.LAYER_ORDER array.
Conclusion
Managing layer order effectively is crucial for creating clear and informative maps in Mapbox GL JS. While Mapbox provides basic ordering mechanisms, they can prove insufficient when dealing with asynchronous operations or dynamic user interactions.
By implementing the ZLayers module, we’ve demonstrated a robust solution to maintain consistent layer ordering regardless of how and when layers are added or removed. This approach offers greater flexibility and control, ensuring your maps always present information in the desired hierarchy, ultimately enhancing the user experience.
This solution, born from a real-world project at Qubika, highlights the power of extending Mapbox GL JS functionality to meet specific application needs. Understanding the core concepts of layer ordering, along with employing creative solutions like the ZLayers module, is a key component in unlocking the full potential of Mapbox GL JS to build dynamic and engaging map experiences.


