



















The power of AI in your pocket
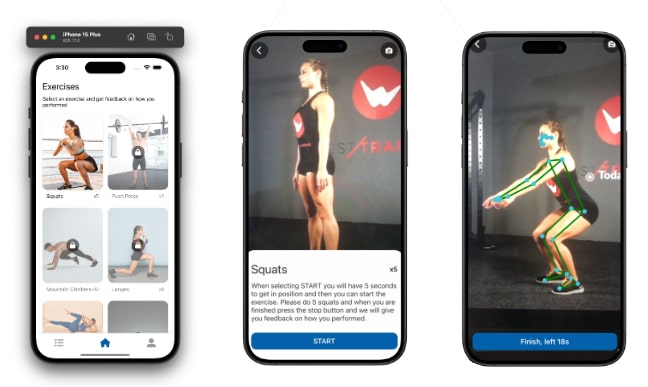
Imagine having a virtual physiotherapist available at all times, providing expert guidance on your exercise form. This is the vision behind our mobile application. Built with React Native, the app allows users to record themselves performing squats. The recorded video is then securely uploaded to Amazon S3 for storage and analyzed by a sophisticated AI-powered backend.
Importance of rapid POCs
Creating proof of concepts (POCs) internally presented several challenges. We needed to accelerate development, showcase our technical expertise, and efficiently validate innovative concepts to stay ahead of the competition. Rapid, high-quality POCs can significantly impact client decisions, making speed and excellence crucial for our success.
Computer vision: The eyes of the AI
The backend utilizes computer vision models, including OpenCV and the pose estimation model YOLO, to analyze the video frame by frame. This process involves identifying key points on the user’s body, such as knees, hips, and shoulders, to calculate angles and evaluate movement patterns. Think of it as the AI meticulously studying your every move, just like a real physiotherapist would.
Personalized feedback and visual guidance
After the analysis is complete, the AI generates personalized feedback, highlighting areas for improvement in the user’s squat technique. But it doesn’t stop there. The backend also creates an overlay video that visually represents the user’s movements with a skeletal structure. This provides a clear and intuitive illustration of their form, making it easier to understand the AI’s feedback. Both the feedback and the overlay video are relayed back to the mobile app, empowering users to take control of their exercise journey.
How it works: A behind-the-scenes look at how computer vision transforms exercise feedback
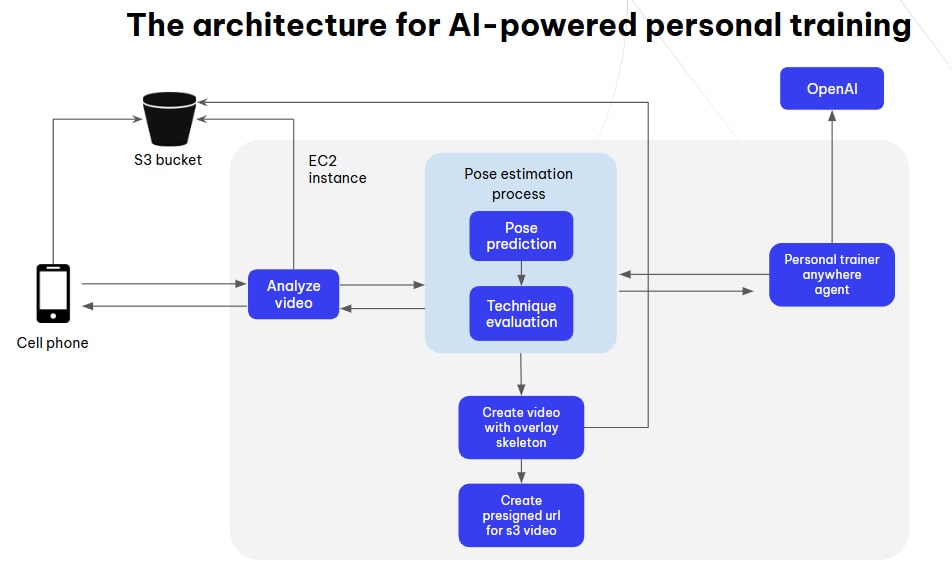
- The mobile app records a video of a person doing squats and uploads it to S3. Once the video is uploaded, the app triggers a call to the /analyze-video endpoint of our backend (FastAPI, deployed on an EC2 instance). It sends the name of the video in S3 and requests an analysis.
- The backend downloads the video from S3 (using IAM user keys that only have put and get permissions for the specific directory in the S3 bucket to maintain least privilege). It then performs pose estimation and extracts key body points (using OpenCV and YOLO), which are sent to a language model (LangChain integrated with OpenAI) for analysis.
- The backend generates a new video with the skeletal overlay (using red and green colors to indicate whether body angles are within certain ranges). The resulting video is uploaded to S3, and a pre-signed URL is created. The backend returns a JSON response to the app, containing the pre-signed URL and the analysis from the language model.
Endpoints
POST /analyze-video
This endpoint is used to analyze a video of a user performing squats. It accepts the name of the video stored in S3, triggers pose estimation on the backend, and returns an analysis of the user’s technique and the video url to s3.
Request Body:
{
"s3_filename": "string", // Name of the video file stored in the S3 bucket
"metadata": { // user's metadata for better analysis
"age": number,
"weight": number,
"height": number,
"gender": "string",
}
}Response:
{
"message": "Video processed successfully"
"analysis": "string", // Analysis of the squat technique (feedback, detected body points, etc.),
"processed_video_uri": "string" // Presigned URL to download the processed video with skeletal overlay
}GET /get-presigned-url
This endpoint generates a presigned URL for the mobile app to retrieve a video stored in an S3 bucket. The URL expires in one week and can be regenerated when needed to allow the app to continuously access the video.
Query parameters
filename: The name of the video file stored in S3 (e.g., squat_video.mp4).
Response:
{
"presigned_url": "string" // Presigned URL to download the processed video with skeletal overlay
}Pose estimation process
A video consists of many images combined together, with each image being a frame. The more frames per second (fps) a video has, the smoother it appears. Typically, videos run at 24fps, 30fps, or 60fps. For this POC, we chose 24fps, to get a faster analysis.
In computer vision, when analyzing a video for pose estimation, we process it frame by frame using a library like OpenCV. For each frame, we make predictions using a pose estimation model (such as YOLO in our case). This model returns the locations (x, y coordinates in the image) of various keypoints in the frame. Keypoints can include points like the right knee, left knee, left hip, right hip, and more. Knowing the position of each keypoint in every frame allows us to perform calculations and extract useful information.
YOLO calculates 17 different keypoints, but in our application, we focus on 8 keypoints: left hip, right hip, left knee, right knee, left shoulder, right shoulder, left elbow, and right elbow.
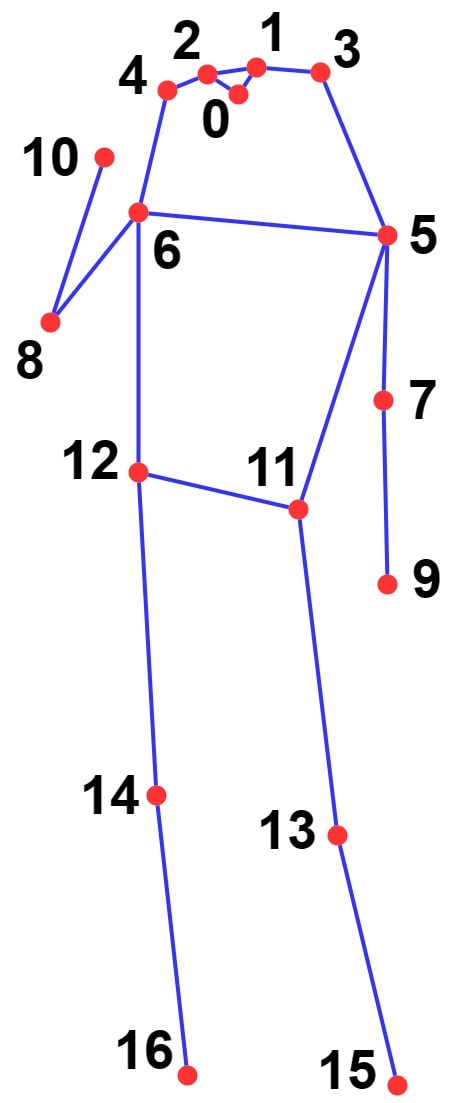
In the pose prediction step, a folder is created containing images corresponding to each frame of the video, along with a JSON file for each frame that includes the predicted keypoints, along with the angles of the knees and the back for each frame.
This information is then used in the performance evaluation, which calculates the number of repetitions, if the angles are in the expected threshold, among other data.
The extracted data of the performance evaluation follows this format, which aids in analyzing squat techniques:
{
"thresholds": {
"left_knee": {
"low": 70,
"high": 100
},
"right_knee": {
"low": 70,
"high": 100
},
"left_hip": {
"low": 70,
"high": 100
},
"right_hip": {
"low": 70,
"high": 100
},
"default": {
"low": 60,
"high": 160
}
},
"exercise_duration": 13.85,
"left_side_repetitions": 3,
"right_side_repetitions": 3,
"green_zone_time": {
"left_knee": 1.8,
"right_knee": 1.32,
"left_hip": 1.28,
"right_hip": 0.92
},
"left_side_time_in_green_zone": 1.04,
"right_side_time_in_green_zone": 0.64,
"all_in_green_zone_time": 0.12
}This data is passed to the LLM (Large Language Model) along with user metadata for further analysis.
To create a video overlaying the skeleton, we similarly process the video frame by frame, adding the skeleton to each frame. We then compile all frames to generate a new edited video. In this video, the angles are displayed in green if they are within the expected range and red if they are not.

FAQs: How computer vision transforms exercise analysis
Q: What is computer vision and how does it apply to exercise?
A: Computer vision is like giving a computer the ability to “see” and interpret images and videos. In the context of exercise, it allows an AI to analyze your movements in detail, similar to how a coach would observe you.
Q: How does computer vision actually “see” me in the exercise video?
A: The AI uses computer vision models (like OpenCV and YOLO) to identify specific points on your body – your joints, limbs, etc. – in each frame of the video. It’s like the AI is drawing a map of your body’s position in every moment.
Q: What does the AI do with this information?
A: By tracking these points across multiple frames, the AI can see how your body moves and calculate important metrics like angles at your joints. This allows the AI to assess your form and technique with high precision.
Q: What are the benefits of using computer vision for exercise analysis?
A:
- Objective feedback. The AI provides unbiased feedback based on your actual movements, eliminating guesswork.
- Detailed analysis. Computer vision can capture subtle nuances in your form that might be missed by the human eye.
- Personalized insights. The AI can tailor feedback to your specific needs and help you identify areas for improvement.
- Injury prevention. By analyzing your form, the AI can help you avoid potentially harmful movements and reduce your risk of injury.
- Increased accessibility. Computer vision makes expert-level analysis more accessible, allowing you to receive guidance anytime, anywhere.
Q: Can computer vision be used for any type of exercise?
A: While the current app focuses on squats, the technology can be applied to a wide range of exercises. The AI can be trained to recognize and analyze different movements, providing valuable feedback for various workout routines.
Q: How does computer vision enhance the feedback I receive?
A: The AI can generate a visual representation of your movements with a skeletal overlay, highlighting correct and incorrect angles. This makes it much easier to understand the analysis and see exactly how to adjust your form.
Explore our Artificial Intelligence Studio
Whether you're looking to enhance your business processes, gain valuable insights from your data, or automate complex tasks, our team of AI experts is dedicated to delivering tailored solutions.


