



















When Data Projects Stop Being “Just Notebooks”
If you’ve worked with Databricks long enough, you’ve probably seen this pattern:
-
Jobs created manually in the UI
-
Slightly different pipelines across dev, staging, and prod
-
Deployments that rely on error prone manual setups
Databricks solves hard problems around scale, performance, and unified analytics. But without structure, even the best platform can turn into operational chaos as teams move beyond experimentation.
At Qubika, we see this challenge repeatedly when organizations transition Databricks workloads from proof-of-concept to production. Teams quickly outgrow notebooks, yet often lack a clear path toward industrialized, repeatable delivery.
That’s exactly where Databricks Asset Bundles come in. A software engineering mindset to data and AI projects, replacing manual configuration with reproducible, versioned, and automatable deployments.
What Exactly Is an Asset Bundle?
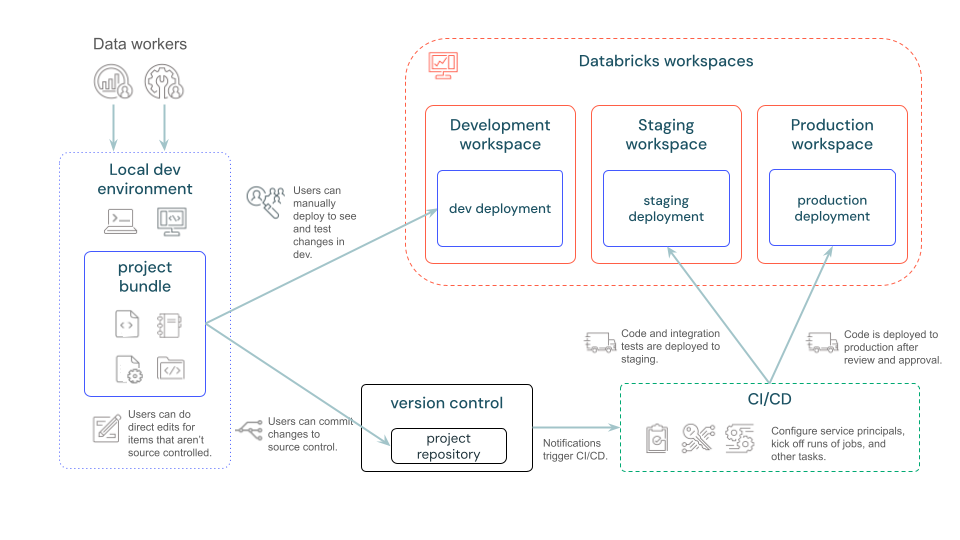
At its core, a Databricks Asset Bundle is a packaged definition of an entire Databricks project.
Instead of configuring jobs, pipelines, dashboards, and ML assets manually in the workspace UI, everything is defined as code, using YAML and source files stored in Git.
A typical Asset Bundle includes:
-
Python, SQL, or notebook source code
-
YAML definitions for jobs, pipelines, dashboards, MLflow assets, and more
-
Environment-specific configuration (dev, staging, prod)
-
Tests and documentation
-
A single entry point:
databricks.yml
Conceptually, the bundle becomes the single source of truth for how a Databricks solution is built and deployed.
At Qubika, we use Asset Bundles as the backbone for delivering Databricks solutions in a clean, repeatable way, especially when projects span multiple teams, environments, or customers.
Why Teams Are Moving to Asset Bundles
Asset Bundles aren’t just a nicer way to organize files. They fundamentally change how teams build, deploy, and operate data platforms.
Reproducible environments without manual drift
The same bundle can be deployed to dev, staging, and prod by changing only configuration values.
This eliminates environment drift and ensures that what gets validated is exactly what reaches production.
Git-first collaboration for data teams
With Asset Bundles, everything lives in source control:
-
Pull requests and code reviews
-
Clear ownership and accountability
-
A complete history of changes
This aligns data projects with the same engineering standards already used by backend and platform teams, something we actively promote in our Databricks engagements.
CI/CD that actually works for data
Bundle deployments are idempotent: Databricks applies only what has changed.
This makes them ideal for CI/CD pipelines, where validation and deployment can run automatically and safely.
We routinely integrate Asset Bundles into CI/CD pipelines to enable continuous delivery of data pipelines, ML workflows, and analytics assets.
Governance built into delivery
Permissions, naming conventions, cluster configuration, and resource definitions are all expressed as code.
This allows governance to be enforced consistently, without slowing teams down or relying on manual controls.
For organizations building or scaling a Databricks Center of Excellence, this provides a strong foundation for standardization and auditability.
What Can You Manage with Asset Bundles?
One of the reasons we’ve adopted Asset Bundles as a default pattern is their broad coverage across the Databricks platform.
Using bundles, we manage:
-
Workflows / Jobs (multi-task orchestration, parameters, schedules)
-
Lakeflow Pipelines (Delta Live Tables)
-
Dashboards
-
MLflow experiments and registered models
-
Model Serving endpoints
-
Clusters and Unity Catalog–governed resources
This enables true end-to-end Databricks delivery, from ingestion to ML inference, using a single, coherent deployment model.
Where We See the Biggest Impact in Real Projects
Collaborative data engineering at scale
For multi-engineer teams, Asset Bundles remove ambiguity and significantly reduce onboarding time. Everyone works against the same definitions, conventions, and deployment process.
Production ML and AI platforms
ML projects benefit enormously from bundles. Training, evaluation, registration, and serving can all be promoted across environments in a controlled and auditable way.
Enterprise governance and compliance
In regulated environments, Asset Bundles provide traceability and repeatability without introducing external tooling or complex custom frameworks.
Databricks CoEs and accelerators
We use Asset Bundles to create reusable templates and accelerators, helping customers move faster while maintaining consistent quality and standards.
How Asset Bundles Fit into Modern Delivery Pipelines
Asset Bundles are built around the Databricks CLI, making them easy to integrate into standard DevOps workflows:
-
Define everything locally in Git
-
Validate changes automatically
-
Preview what will be deployed
-
Deploy to target environments
-
Trigger workflows programmatically
This allows data teams to operate with the same delivery maturity as platform and application teams, a pattern we consistently implement in Databricks projects.
Practical Considerations Before Adopting
Asset Bundles do introduce an important mindset shift:
-
Bundle-managed resources shouldn’t be edited directly in the UI
-
The bundle becomes the single source of truth
-
Manual changes outside the bundle will be overwritten
From our experience, the transition is absolutely worth it, but it should be planned.
Many teams start by bundling new workloads first, then gradually migrating stable, existing jobs once the process is well understood.
Final Thoughts: How We Build on Databricks at Qubika
Databricks Asset Bundles are more than just a feature. They signal that data and AI platforms deserve the same engineering discipline as any other production system.
At Qubika, we use Asset Bundles to:
-
Deliver production-grade Databricks solutions
-
Enable CI/CD for data and ML workloads
-
Enforce governance without friction
-
Scale Databricks adoption across teams and organizations
For teams serious about operating Databricks at scale, Asset Bundles aren’t just helpful, they’re foundational.
Explore our Databricks services
Qubika is a Databricks Gold Partner with 200+ certified engineers across data, AI, and ML. Whether you're adopting Lakeflow, migrating existing pipelines, or designing a lakehouse from scratch, our team brings hands-on platform experience to every engagement.


