Why the Lakehouse Architecture Is the Next Step
![]()
Snowflake has an established track record as a leader in cloud data warehousing, offering scalability, performance, and ecosystem maturity. However, as data strategies evolve, some organizations find strategic or technical advantages in transitioning from Snowflake to Databricks.
The Databricks Lakehouse Platform represents a next-generation approach to data management. It integrates data engineering, analytics, and machine learning within a unified, governed architecture built on Delta Lake. This convergence supports the emerging AI-native data ecosystem, enabling enterprises to operationalize AI and analytics at scale.
This article outlines how to approach and execute a migration from Snowflake to Databricks, providing guidance on best practices, sequencing, and architectural considerations to ensure a successful transition.
The Migration Framework
Successful migrations follow a structured, five-phase framework. Qubika has operationalized this framework with automation, validation, and accelerators to ensure repeatable, low-risk delivery.
|
Phase |
Objective |
|---|---|
|
Inventory current workloads, complexity, and cost hotspots. |
|
Map Snowflake components to their Lakehouse equivalents (Streams → Delta CDF, Tasks → Workflows, Snowpipe → Auto Loader) and define the transient coexistence period. |
|
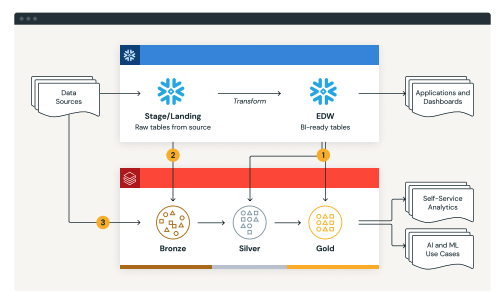
Move data into Delta Lake’s Bronze/Silver/Gold layers, leveraging COPY INTO and Auto Loader, or the Spark Snowflake Connector for smaller datasets. |
|
Refactor ETL to Spark SQL and Declarative Pipelines, using Lakeflow Jobs for orchestration and validation. |
|
Repoint BI tools (Power BI, Tableau, Looker) to Databricks SQL Warehouses and validate report parity. |
Two strategies dominate successful migrations:
-
ETL-first, migrate ingestion and transformations first, keeping Snowflake temporarily for BI.
-
BI-first, replicate the reporting layer first, then rebuild the ETL stack.
Both strategies can coexist during a transient architecture phase, with data flowing in parallel between Snowflake and Databricks until cutover completion.
The Advantages of the Lakehouse Approach
1. Unified Data and AI
Databricks runs analytics, data science, and machine learning on the same Delta tables, removing the silos between data engineers and data scientists. Built-in tools like MLflow, Feature Store, and AutoML enable full MLOps lifecycle management.
2. Open Formats, No Lock-In
Unlike Snowflake’s proprietary FDN format, Delta Lake uses open Parquet files with ACID transactions, schema evolution, and versioned data access.
3. Performance and Cost Efficiency
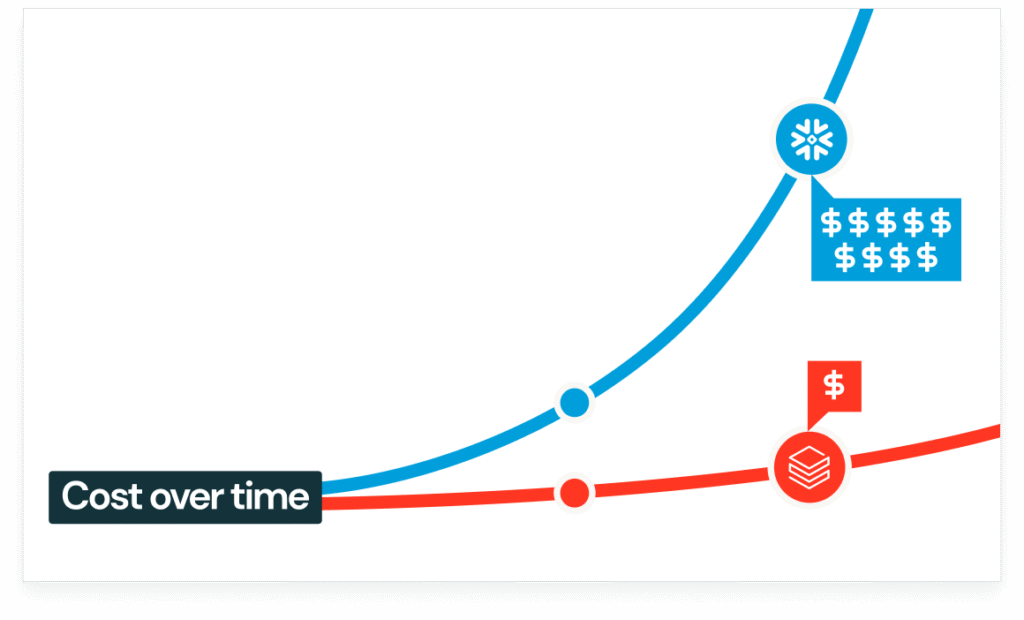
Replace fixed virtual warehouses with elastic Databricks clusters and Photon-powered SQL Warehouses, achieving up to 3× performance gains for analytical queries and large-scale transformations.
4. Advanced Governance
The Unity Catalog centralizes fine-grained access control, lineage, and auditability across SQL, Python, and R, something Snowflake achieves only with external tools. This single governance layer is key to operating a modern data warehouse at scale.
5. Modern ELT and Streaming
Snowpipe and Tasks are replaced by Auto Loader and Delta Live Tables (DLT), enabling streaming ingestion, built-in data quality tests, and self-healing pipelines. This modern approach reduces ingestion latency from hours to minutes.
6. Flexible Modernization Paths
Organizations can choose lift-and-shift, hybrid, or full data warehouse modernization. Both ETL-first and BI-first strategies are validated by Databricks, offering flexibility depending on business priorities.
Unlocking Value Beyond Migration
Qubika’s Snowflake-to-Databricks projects span industries, but the impact is consistent: faster performance, lower costs, and new AI capabilities.
Example: A financial institution migrated hundreds of Snowflake ETL jobs across business units. After the discovery assessment, Qubika prioritized high-cost workloads and adopted an ETL-first strategy. Data was landed in Delta Lake’s Bronze/Silver/Gold layers, and dashboards were re-pointed to Databricks SQL.
Outcomes:
-
40–45% compute cost reduction
-
3× faster ETL performance
-
Real-time analytics for compliance and fraud detection
Common post-modernization use cases:
-
AI-powered Q&A over thousands of financial documents
-
Centralized governance under a single Unity Catalog
-
Unified analytics across structured and semi-structured data (JSON, logs, CSVs)
-
Streaming pipelines for near real-time insight delivery
Each outcome demonstrates how Databricks turns what was once a static warehouse into a dynamic, AI-driven data platform.
Getting Started with the Migration
1) Assess Your Snowflake Environment
Run the Snowflake Profiler to analyze workloads and costs, and the BladeBridge Analyzer to classify code complexity (DDL, stored procedures, views).
2) Define Your Migration Strategy
Decide between:
-
Lift-and-Shift (ETL-first), move ingestion/transformation workloads first.
-
BI-First, migrate presentation layers first.
-
Hybrid, start small, then progressively modernize both.
3) Migrate Data
Use the recommended COPY INTO → Parquet → Auto Loader → Delta pattern, or the Spark Snowflake Connector for small tables
For real-time sync, leverage the Snowflake Stream Reader or CDC partners like Arcion via Partner Connect.
4) Migrate and Refactor Pipelines
Convert Snowflake SQL to Spark SQL using BladeBridge Converter or SQLGlot, then orchestrate with Lakeflow Jobs or Lakeflow Declarative Pipelines for reliability.
5) Validate and Cut Over
Perform a sink-to-sink data validation. Compare record counts, sums, and schema consistency. Maintain both systems in parallel for 1–2 weeks before final cutover.
6) Optimize Post-Migration
Follow Databricks’ performance tuning best practices:
-
Partition large tables carefully, targeting > 1 GB file sizes.
-
Use Liquid clustering on high-cardinality columns (up to 5 keys).
These tuning techniques, deliver sustained performance and cost efficiency after go-live.
Modernization, Not Just Migration
Migrating from Snowflake to Databricks can represent a strategic modernization of your data foundation.
By adopting the Lakehouse architecture, you unify analytics, governance, and AI in a single platform. You move from proprietary silos to open, flexible ecosystems, capable of powering real-time analytics, machine learning, and cross-domain collaboration.
At Qubika, our mission is to make that transition seamless. Through Databricks’ proven five-phase methodology, automation accelerators, and industry expertise, we turn data migrations into data transformations, delivering a modern data lakehouse that’s ready for the AI era.