


















Notebook Pipelines Were Flexible, but Not Always Predictable
For a long time, Databricks pipelines were built around notebooks plus Jobs orchestration.
That approach offers flexibility, but it also introduces challenges:
-
Execution order lives outside the code
-
Dependencies are implicit
-
Incremental logic is hand-written
-
Observability is split between multiple interfaces
-
CI/CD requires additional plumbing
As data platforms scale, these trade-offs become harder to manage.
The Lakeflow Pipeline Editor represents a structural change: pipelines are no longer a sequence of notebooks, they are declarative assets defined in code files.
What the Lakeflow Pipeline Editor Changes
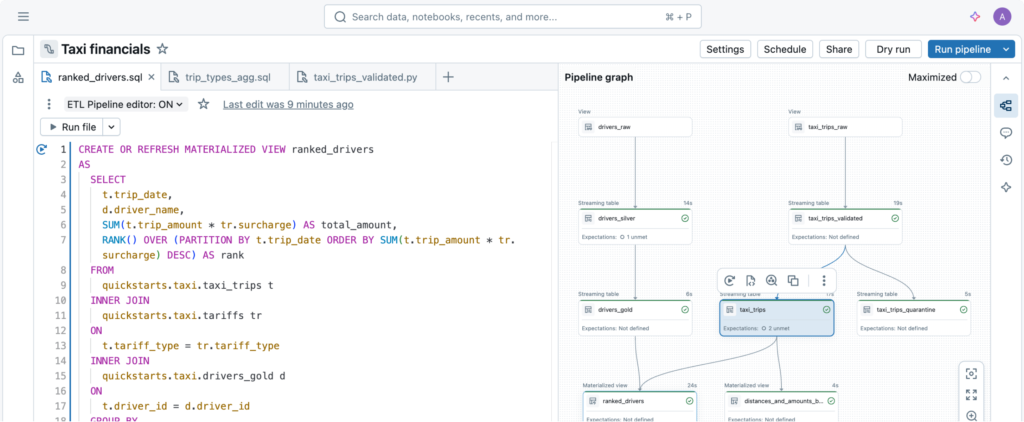
The Lakeflow Pipeline Editor is an IDE designed for Spark Declarative Pipelines (formerly DLT) .
Instead of imperatively orchestrating transformations, you define datasets:
-
Streaming tables
-
Materialized views
-
Views
From these definitions, Databricks automatically derives:
-
Dependency graphs
-
Execution order
-
Parallelism
-
State handling
-
Incremental semantics
This shifts the responsibility from the developer writing orchestration logic to the framework managing it deterministically.
The conceptual model is important:
A pipeline becomes a single logical unit composed of dataset definitions, not a collection of loosely related notebooks.
File-Based Development Instead of Notebook Cells
One of the biggest technical shifts is the move to file-based authoring.
Compared to notebook-driven pipelines:
-
Logic is split across modular Python/SQL files
-
Folder structure enforces separation of concerns
-
Git workflows become natural (diffs, code reviews, branching)
-
Ownership and change tracking improve
The editor provides pipeline-specific capabilities that generic notebooks do not :
-
Multi-file navigation
-
Table-level run controls
-
An issues panel across files
-
Integrated DAG visualization
DAG as a First-Class Concept
In notebook + Jobs workflows, the DAG is implicit, defined by job task order or manual orchestration.
In Lakeflow, the DAG is derived directly from dataset definitions.
The editor generates a live, interactive dependency graph that allows you to:
-
Inspect upstream/downstream relationships
-
Jump from nodes to source code
-
Execute specific tables
-
View execution state at the dataset level
This reduces ambiguity and makes reasoning about complex pipelines significantly easier.
Incremental Processing and CDC Are Built In
Traditional Spark jobs often implement incrementality manually:
-
Watermarks
-
Merge logic
-
Change Data Capture handling
-
Custom retry logic
Lakeflow provides declarative constructs for:
-
Streaming tables
-
Materialized views
-
Auto-CDC (SCD Type 1 / Type 2)
-
Expectations (data quality rules)
Instead of coding incremental logic imperatively, you describe desired dataset behavior, and the engine enforces incremental semantics.
This reduces boilerplate but also imposes structure, pipelines must conform to the declarative model.
Execution Model and Compute Behavior
Lakeflow uses standard Databricks compute (job clusters or serverless), but its execution model has implications :
-
Only new or changed data is processed for incremental datasets
-
Independent tables can execute in parallel
-
Failures retry at the table level instead of re-running the entire pipeline
-
Serverless startup improves short execution cycles
In many ETL scenarios, this results in:
-
Reduced reprocessing
-
Lower wall-clock time
-
More predictable execution patterns
However, cost and performance still depend on:
-
Dataset design
-
Data volume and velocity
-
Trigger frequency
-
Warehouse sizing
The framework improves efficiency, but it does not eliminate the need for architectural discipline.
Observability and Operational Behavior
A key technical improvement is unified monitoring.
From the pipeline monitoring surface , you can access:
-
Historical runs
-
Execution metrics
-
Data quality results
-
Errors and warnings
This replaces the fragmented debugging workflow of:
-
Rerunning notebooks
-
Inspecting Spark UI
-
Checking Jobs logs separately
Operationally, Lakeflow enforces:
-
Deterministic orchestration
-
Fine-grained retries
-
Managed state
This reduces operational glue code that teams previously had to maintain themselves.
Constraints and Engineering Trade-Offs
Lakeflow is not a drop-in replacement for every Spark workload.
Some considerations from the documentation :
-
Public preview status
-
Certain Spark functions (e.g., pivot) are restricted
-
Some advanced features require workarounds
-
200 concurrent pipeline update limit per workspace
-
Declarative model reduces flexibility compared to raw Spark
In other words, Lakeflow optimizes for structure and reliability, not maximum flexibility.
For highly custom Spark logic or ML experimentation, notebooks plus Jobs may still be more appropriate.
Architectural Positioning
Lakeflow is best suited for:
-
Standard ETL pipelines
-
CDC-driven transformations
-
Silver/Gold layer construction
-
Pipelines requiring strong governance and CI/CD alignment
It integrates naturally with:
-
Git
-
Asset Bundles
-
Unity Catalog
-
Serverless compute
Databricks explicitly recommends file-based development for new pipelines .
From an architectural standpoint, this signals a long-term direction:
Declarative, modular pipelines as the default production pattern.
Final Thoughts
The Lakeflow Pipeline Editor is less about UI convenience and more about enforcing a different engineering model.
It moves pipeline development:
-
From implicit to explicit
-
From notebook-centric to asset-centric
-
From manual orchestration to framework-managed execution
-
From flexible scripting toward structured declarative design
For teams building production-grade data platforms on Databricks, this shift is significant.
It doesn’t eliminate complexity, it relocates it into a deterministic execution framework.
And for many ETL and CDC use cases, that trade-off is worthwhile
Explore our Databricks services
Qubika is a Databricks Gold Partner with 200+ certified engineers across data, AI, and ML. Whether you're adopting Lakeflow, migrating existing pipelines, or designing a lakehouse from scratch, our team brings hands-on platform experience to every engagement.


