


















The new baseline for data engineering
AI is changing how software gets built. The same shift is happening in data engineering.
At Qubika, we are not treating AI as a side experiment or a productivity toy. We are building it into the way our Data Engineers work every day.
The goal is simple: help strong engineers move faster, with better consistency, stronger governance, and less time spent on repetitive implementation work.
That is why we are building the Qubika Data Engineering AI Dev Kit. It is an internal accelerator designed to help our Data Engineers create production-oriented data assets faster, while keeping security, governance, and engineering standards at the center.
This post is not a deep technical walkthrough of the kit. It is a practical example of what this new way of working looks like.
A real example: from CRM source to governed data product
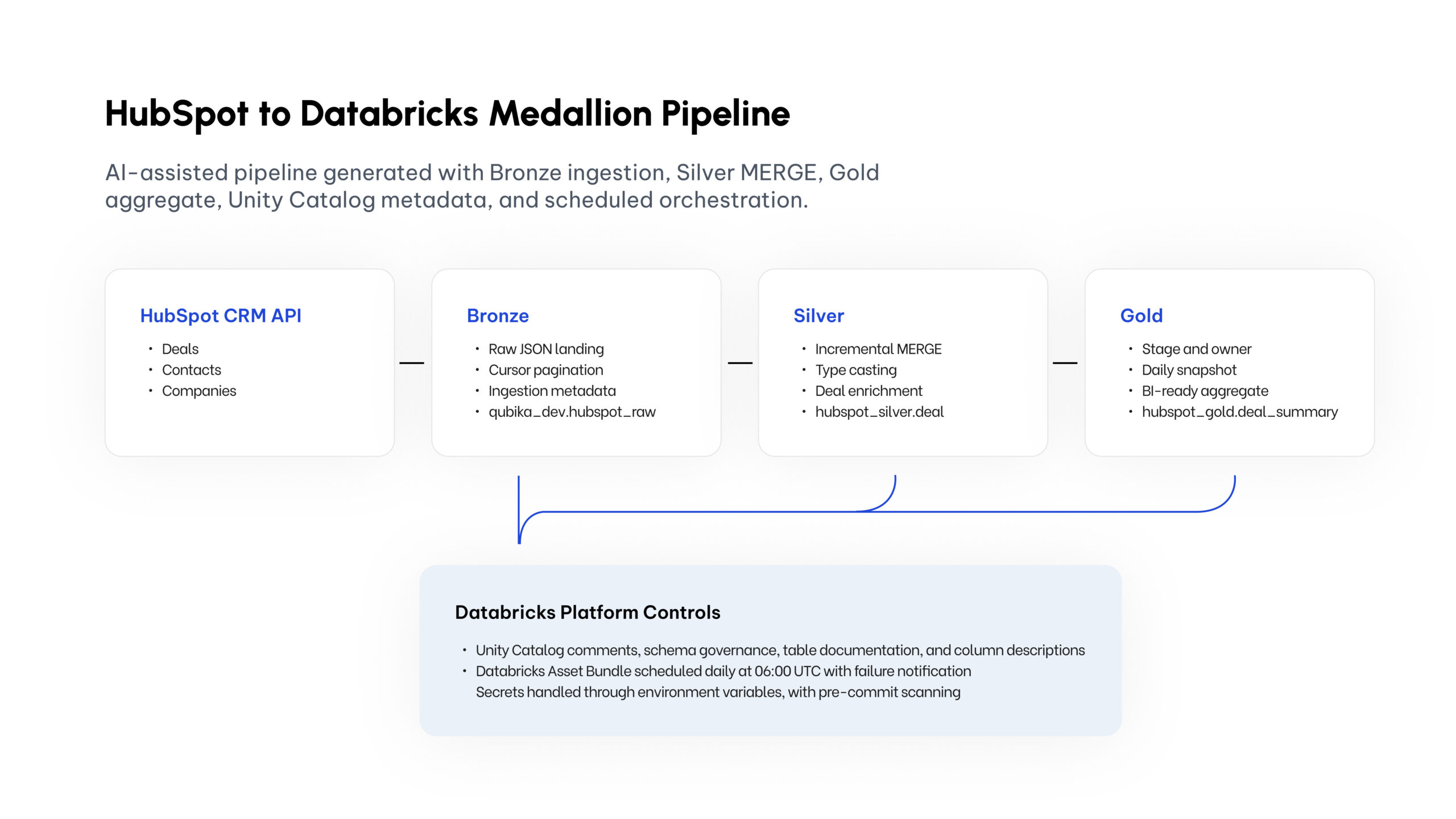
As a test, I used the kit to accelerate the creation of a HubSpot pipeline on Databricks.
The objective was to move from a CRM source into a governed medallion-style data model, with ingestion, transformation, business-level aggregation, metadata, orchestration, testing, and review support.
The result was a complete pipeline structure in minutes, not hours. But the most important part was not the speed. The important part was that the output followed a consistent engineering pattern.
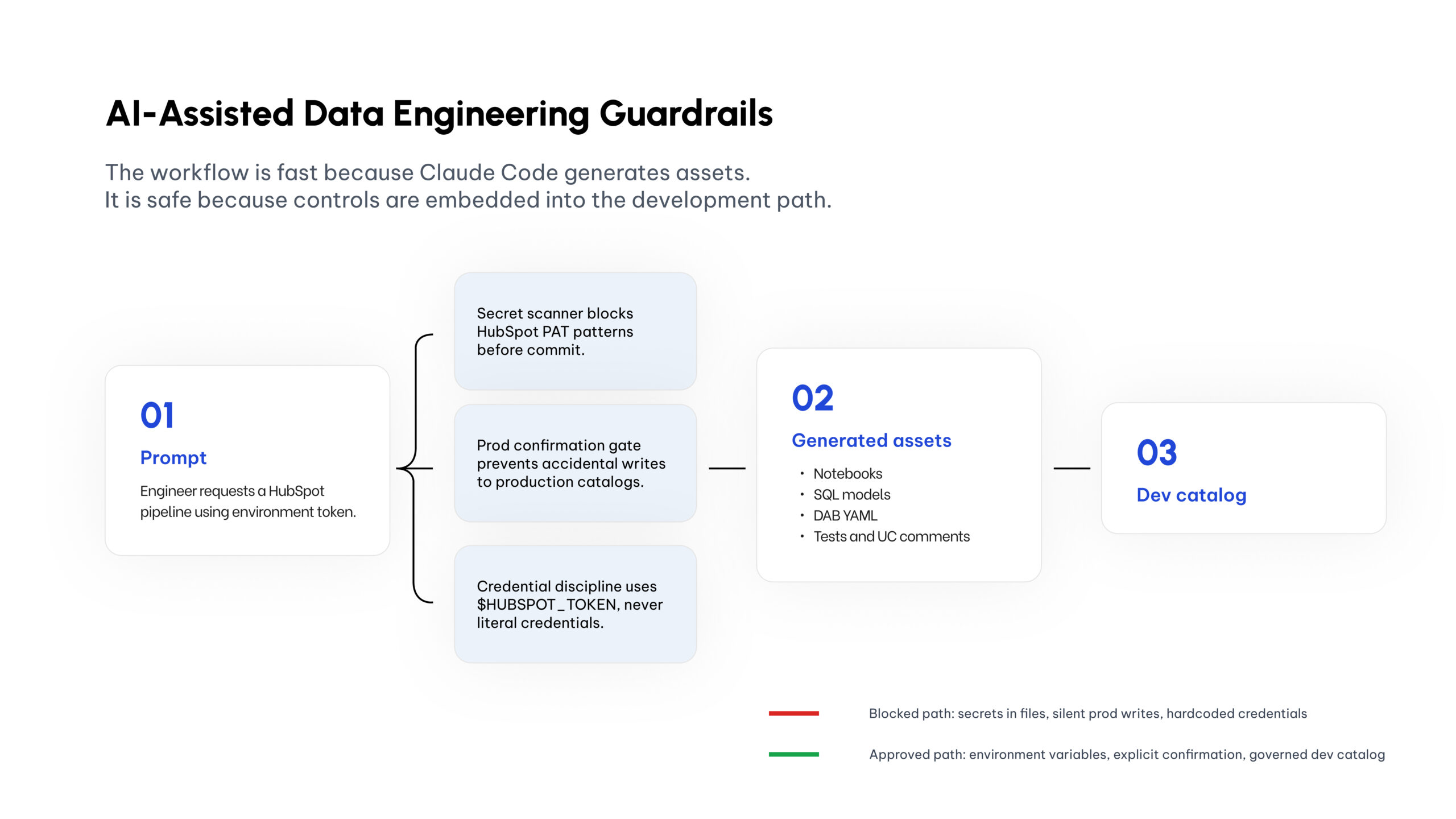
This is the type of work every data engineering team knows well: source ingestion, modeling, quality, metadata, orchestration, and deployment structure.
These are critical tasks, but a lot of the implementation is repetitive. The real engineering judgment is in the design decisions: what to ingest, how to model the data, what quality rules matter, how to govern access, and how to make the data useful for the business.
That is where the kit helps. It does not remove the engineer from the process. It gives the engineer a stronger starting point.
What the Qubika DE AI Dev Kit adds
The kit is more than a prompt or a coding assistant setup. It combines AI coding workflows with reusable Data Engineering skills, project configuration, quality standards, security checks, and usage tracking.
At a high level, it gives our engineers:
- A faster way to generate standard pipeline structures
- Reusable patterns for medallion architecture, governance, ingestion, testing, and monitoring
- Built-in guardrails for credentials, environments, and production safety
- A way to convert team knowledge into reusable skills
- A mechanism to track AI usage and cost by feature or initiative
- A workflow that keeps the engineer in control of decisions before assets are created
The six capabilities the kit gives our engineers, all organized around the data engineer rather than around the AI.
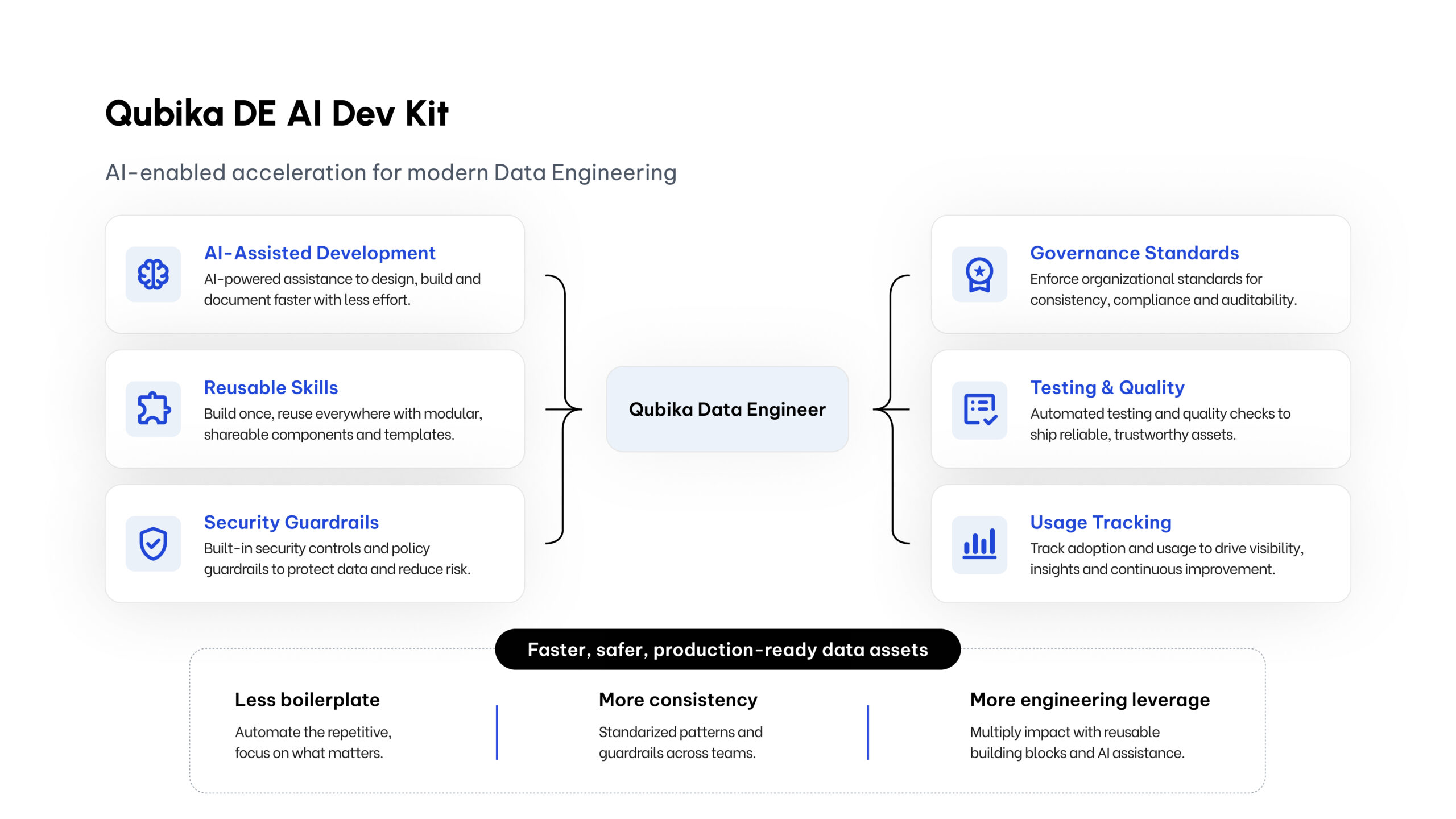
The goal is not to let AI freely generate whatever it wants. The goal is to make AI work inside Qubika’s engineering standards. That distinction matters
Anyone can open an AI coding assistant and ask it to generate a script. That is useful, but it is not enough for enterprise data engineering.
Enterprise data work needs repeatability. It needs platform conventions. It needs governance. It needs security. It needs reviewable outputs. It needs alignment with how the team actually builds.
The Qubika DE AI Dev Kit adds that layer around AI. It helps the assistant understand the patterns our team expects: medallion architecture, naming conventions, Unity Catalog-oriented governance, testing expectations, monitoring patterns, and safe development workflows.The value is not only that AI writes code faster. The value is that AI helps engineers produce outputs that are closer to the way the team wants to build.
The role of reusable skills
One of the most powerful ideas behind the kit is the concept of reusable skills. A skill captures a repeatable engineering pattern. For example:
- How we structure Bronze, Silver, and Gold layers
- How we apply governance metadata
- How we think about data quality checks
- How we build ingestion patterns
- How we test pipelines
- How we monitor production data assets
- How we approach migration to Databricks
Instead of keeping this knowledge only in people’s heads, the kit helps turn it into reusable team intelligence. That means every improvement can become part of the next engineer’s workflow.
This is how the team compounds knowledge. Every good pattern can be reused. Every lesson learned can become part of the system. Every engineer can start from a stronger baseline.
Speed with control
In the HubSpot example, the kit helped generate the skeleton and implementation path for a full data pipeline much faster than a manual build. But speed without control is not good enough.
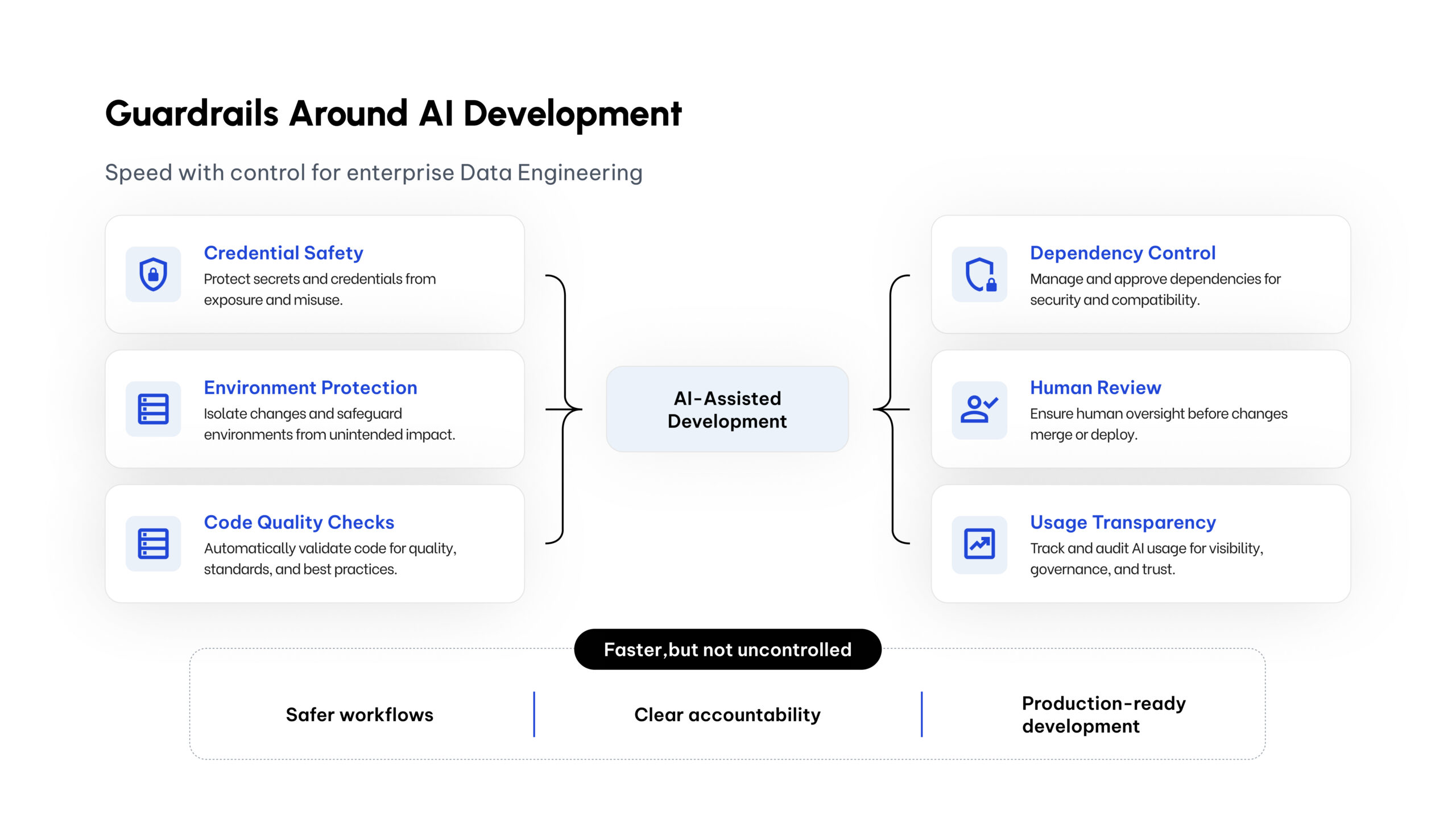
The kit is designed to keep the engineer in the loop. Before creating assets, the workflow asks for key confirmations. It helps avoid accidental environment mistakes. It keeps credentials out of generated code. It supports review before promotion. It encourages consistent documentation and testing.

This is the operating model we want: faster execution, but not uncontrolled execution. The engineer remains accountable for architecture, quality, governance, and production decisions.
Security is part of the product, not an afterthought
A major focus of the kit is safety. We are using the best ideas from modern AI-assisted development workflows, but adapting them to the reality of enterprise Data Engineering.
That means adding layers such as:
- Secret scanning before code is committed
- Additional checks in the CI workflow
- Environment-aware configuration
- Confirmation gates before sensitive actions
- Dependency controls
- Team-level directives for how AI should behave
- Cost and usage tracking for transparency
The six guardrails that wrap every AI-assisted action — designed so the engineer rarely sees them, except when they prevent a mistake.
This is essential. If a company wants to use AI seriously in engineering, it cannot only ask, “How fast can we generate code?” It also needs to ask:
- How do we avoid leaking credentials?
- How do we avoid accidental production changes?
- How do we keep outputs aligned with our standards?
- How do we make the work reviewable?
- How do we measure cost and impact?
Those questions are part of the kit’s design.
What this means for our Data Engineers
The kit is being built to accelerate our Data Engineers, not replace them. It removes friction from the parts of the job that are repetitive — and gives engineers more time to focus on higher-value work.
Less of this
- Pipeline scaffolding
- Standard ingestion patterns
- SQL model structure
- Metadata documentation
- Test boilerplate
- Orchestration templates
- Review checklists
More of this
- Understanding the business problem
- Designing the right data model
- Defining quality rules
- Tradeoffs between latency, cost, and complexity
- Creating trusted data products
- Helping clients move from raw data to real outcomes
A Data Engineer using AI well is not just faster. They are more leveraged. They can bring more of the team’s best practices into every project. They can move from idea to working asset faster. They can spend more time on judgment and less time on boilerplate.
Why this matters for clients
For clients, this translates into a better delivery model. Faster does not only mean “less time.” It means:
- Faster discovery-to-implementation cycles
- More consistent engineering patterns
- Stronger governance from the beginning
- Better documentation and reviewability
- More time spent on business logic and data quality
- A clearer path from prototype to production
Why the foundation matters. AI initiatives depend on strong data foundations. If the underlying data pipelines, models, and governance are weak, the AI layer becomes fragile. By accelerating Data Engineering with AI, we also accelerate the foundation required for analytics, BI, machine learning, and agentic AI.
The bigger picture
The HubSpot example is just one use case. The bigger idea is a repeatable AI-assisted delivery model for data platforms.
From client need to business value — with AI, reusable patterns, and guardrails between every step.
We are building a system where each engineer can work with the leverage of the broader team. That is what excites me the most. Not just one engineer moving faster — a whole Data Engineering practice getting better every time we capture a pattern, improve a skill, or add a guardrail.
Final takeaway
AI-assisted development is becoming part of the modern data engineering toolkit. At Qubika, we are taking that seriously. The Qubika DE AI Dev Kit is our way of bringing AI into Data Engineering with the right balance: speed, quality, governance, and security.
The point is not to expose every implementation detail. The point is to show where the industry is going — Data Engineers working with AI-native workflows, reusing team intelligence, applying stronger guardrails, and delivering production-oriented data assets faster.
That is the standard we are building toward. And that is the kind of Data Engineering team we want to be: faster, safer, more consistent, and at the vanguard of AI-enabled delivery.



