



















Executive summary
If you’re leading data strategy right now, you’re probably living a familiar tension: the business wants faster decisions and AI-ready data, while your teams are juggling a patchwork of warehouses, lakes, pipelines, notebooks, and governance tools that don’t naturally line up.
Databricks is one of the clearest “platform answers” to that tension. In their own words, it’s a unified, open analytics platform for building and operating enterprise-grade data, analytics, and AI solutions, where the platform integrates with your cloud storage and security, and handles infrastructure deployment and management for you.
What makes it strategically interesting isn’t any single feature. It’s the lakehouse operating model: reliable, governed table semantics (Delta Lake) and unified governance (Unity Catalog) directly on top of scalable object storage, so the same foundation serves data engineering, BI, streaming, and ML without copying data across systems.
The most honest description of the value: Databricks reduces the organizational cost of doing data, especially when you need the same data to power both BI and AI. It’s built to address the classic failure modes of keeping a separate lake and warehouse: isolated systems, duplicated costs, stale datasets.
“If your organization’s pain is mostly ‘we can’t govern or reuse data across teams,’ treat Unity Catalog design as a first-week decision, not a phase 2 enhancement.”
Architecture
How the platform fits together
The mental model I use with leadership teams: Databricks separates where you manage things from where compute runs, then sits your data on open storage formats with a unified governance layer on top.
The control plane is Databricks-managed. It’s the web application, the identity layer, the orchestration service, and Unity Catalog. The compute plane is where your data actually gets processed: either in a serverless plane managed by Databricks, or in a classic plane running inside your own cloud account. That distinction matters a lot for risk reviews, networking, and compliance conversations.
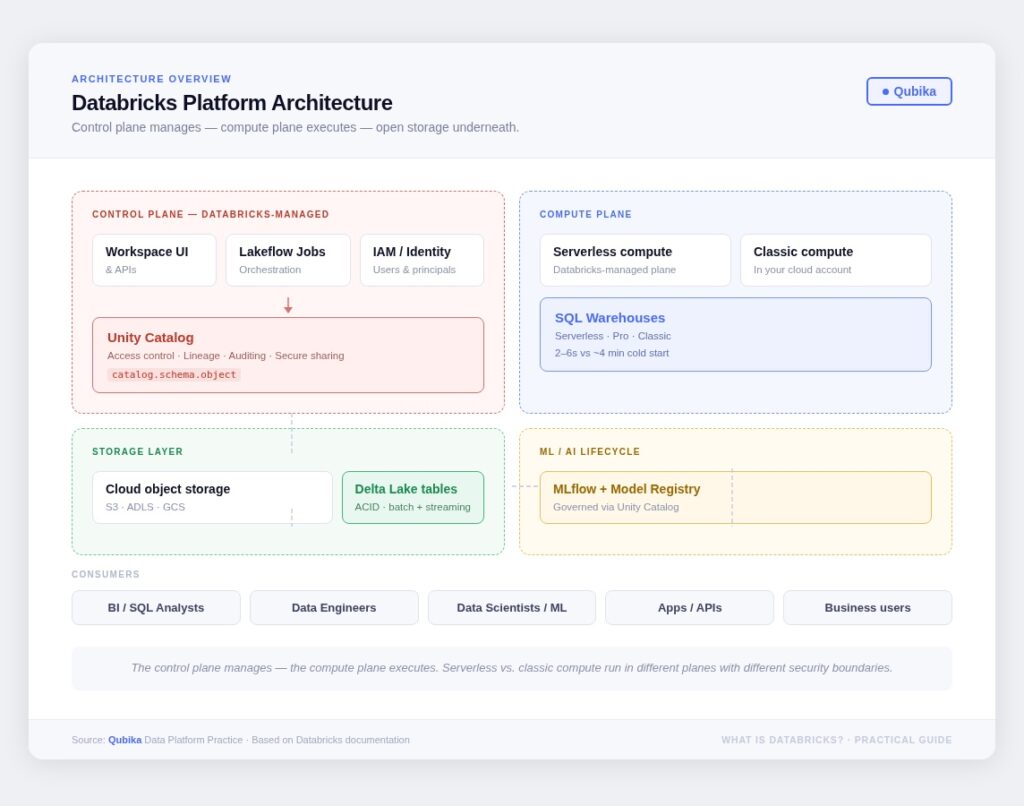
The distinction between serverless and classic compute matters more than it sounds. Serverless runs within a Databricks-managed network boundary; classic runs in your cloud account with natural isolation at the account level. For risk reviews, compliance teams, and anyone thinking about network topology, this is the conversation to have early, not during a production incident.
Platform components
The pieces worth understanding
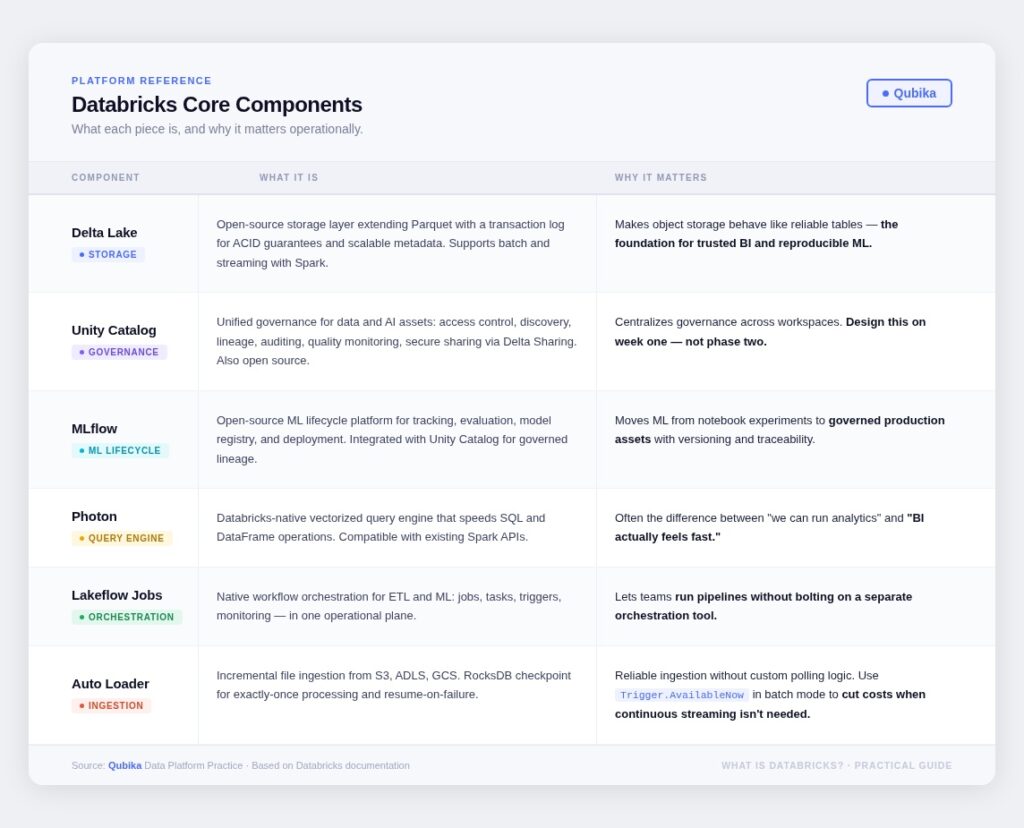
There’s a lot of surface area to Databricks. These are the components I’d make sure any leader walking into an evaluation actually understands: what each one is, and why it matters operationally.
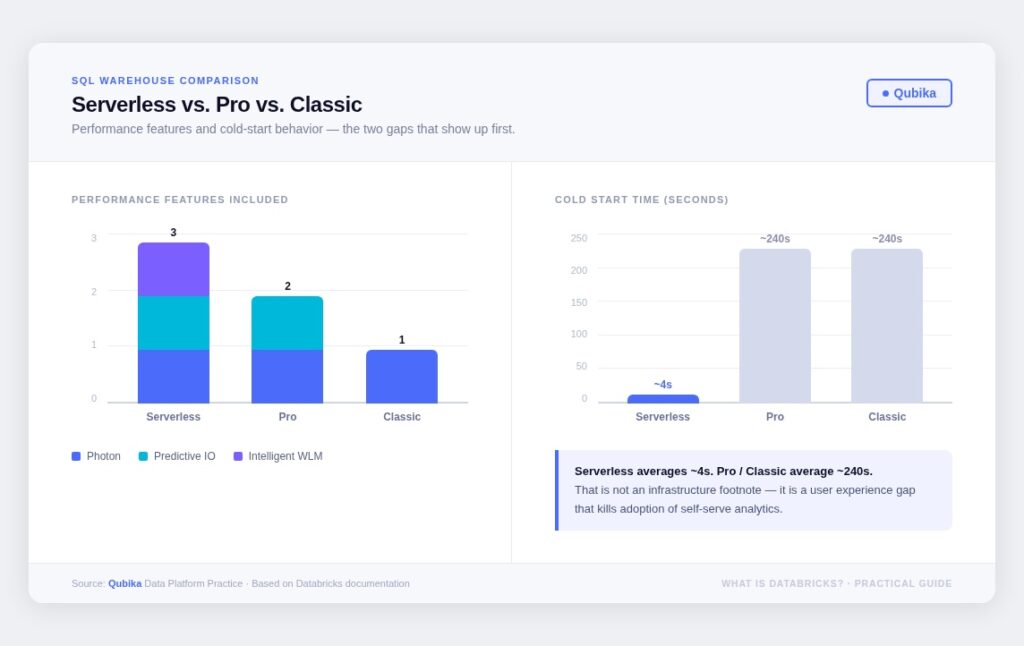
SQL Warehouses: a decision, not a default
Serverless, Pro, and Classic SQL warehouses differ in both included performance capabilities and operational behavior. The performance gap is real, but the startup time gap is the one that shows up first in BI adoption. Serverless cold-starts in 2–6 seconds. Pro and Classic take roughly 4 minutes. That’s not an infrastructure footnote, it’s a user experience problem that kills adoption of self-serve analytics.
Go deeper · Qubika blog
Choosing the Right Way to Serve Workloads in Databricks
Databricks App, Job API, SQL Warehouse, or MCP for AI agents? A practical decision guide to avoid the confusion. →
Governance
Unity Catalog: the governance backbone
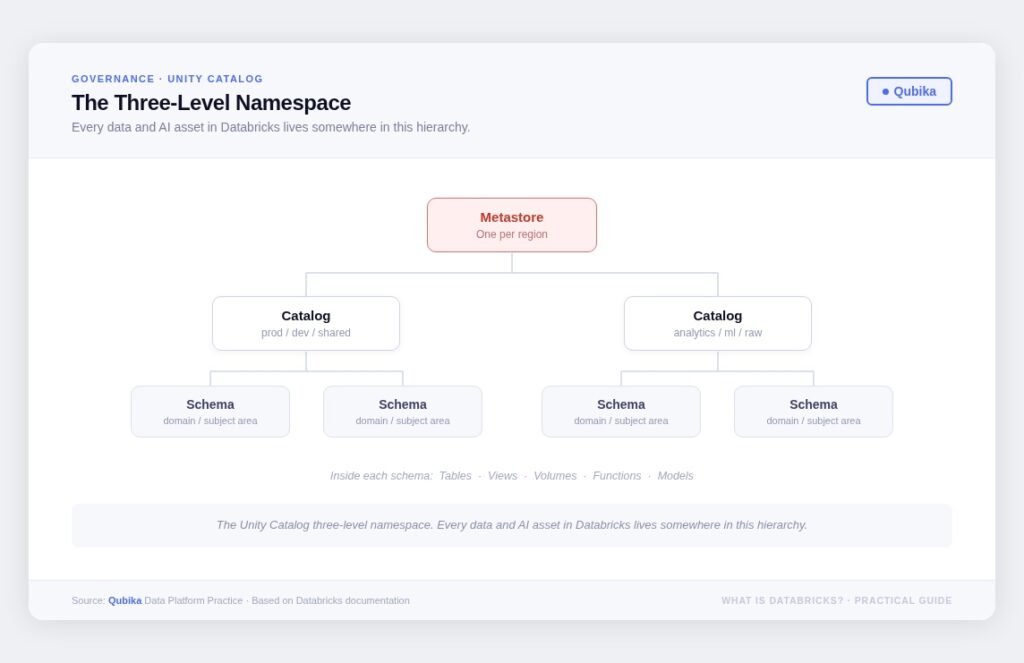
Unity Catalog is built around a metastore and a three-level namespace: catalog.schema.object. Everything (tables, views, volumes, functions, models) lives inside a schema, schemas inside catalogs, catalogs inside a metastore. The governance model covers access control, lineage, auditing, quality monitoring, and secure sharing through Delta Sharing.
The most important thing to understand about Unity Catalog is what it can’t do: it enforces policy, but it can’t invent accountability. You still need to define data ownership, naming conventions, and approval workflows. The platform is a substrate, your governance design is what makes it work.
Cost model
DBUs, quotas, and building cost transparency
Databricks pricing is consumption-based. A DBU (Databricks Unit) is a normalized unit of processing power. Usage is driven by compute resources consumed and the amount of data processed. The model is pay-as-you-go, but without guardrails, costs can creep in ways that surprise teams.
The good news: Databricks surfaces cost data through system tables (system.billing.usage joined with system.billing.list_prices), and supports serverless compute quotas as a safety mechanism. The bad news: most teams don’t build the dashboards until they’ve already had a surprise bill.
Go deeper · Qubika blog
Understanding Databricks costs through System Tables
Understanding Databricks costs through System Tables – Qubika
Recommendation
Put three dashboards in place during your pilot: cost per pipeline run, cost per dashboard refresh, and cost per model training cycle. The data is there, your governance posture decides whether you use it. This is not a “later” task.
Qubika series·Cost-First Design in Databricks
|
01 |
Databricks Cost Series Part 1: Cost-First Design: the Real Driver of Databricks Costs |
|
|---|---|---|
|
02 |
Databricks Cost Series Part 2: Serverless vs Classic: How to Choose Without Guessing |
Databricks Cost Series Part 2: Serverless vs Classic: How to Choose Without Guessing – Qubika |
|
03 |
Databricks Cost Series Part 3: DLT, Monitoring & Photon: Hidden Cost Multipliers |
Databricks Cost Series Part 3: DLT, Monitoring & Photon: Hidden Cost Multipliers – Qubika |
|
04 |
Databricks Cost Series Part 4: From Design to Numbers : Estimating and Governing Databricks Costs |
|
|
05 |
Databricks Cost Series Part 5: Benchmarks, Dashboards and Cost Governance in Practice |
Databricks Cost Series Part 5: Benchmarks, Dashboards and Cost Governance in Practice – Qubika |
Platform comparison
How Databricks fits against the alternatives
This isn’t about “who wins.” It’s about matching platform economics and operating model to your actual workload. The comparison I run most often is Databricks vs. Snowflake (they’re frequently the two on the shortlist), but the honest answer depends on what you need.
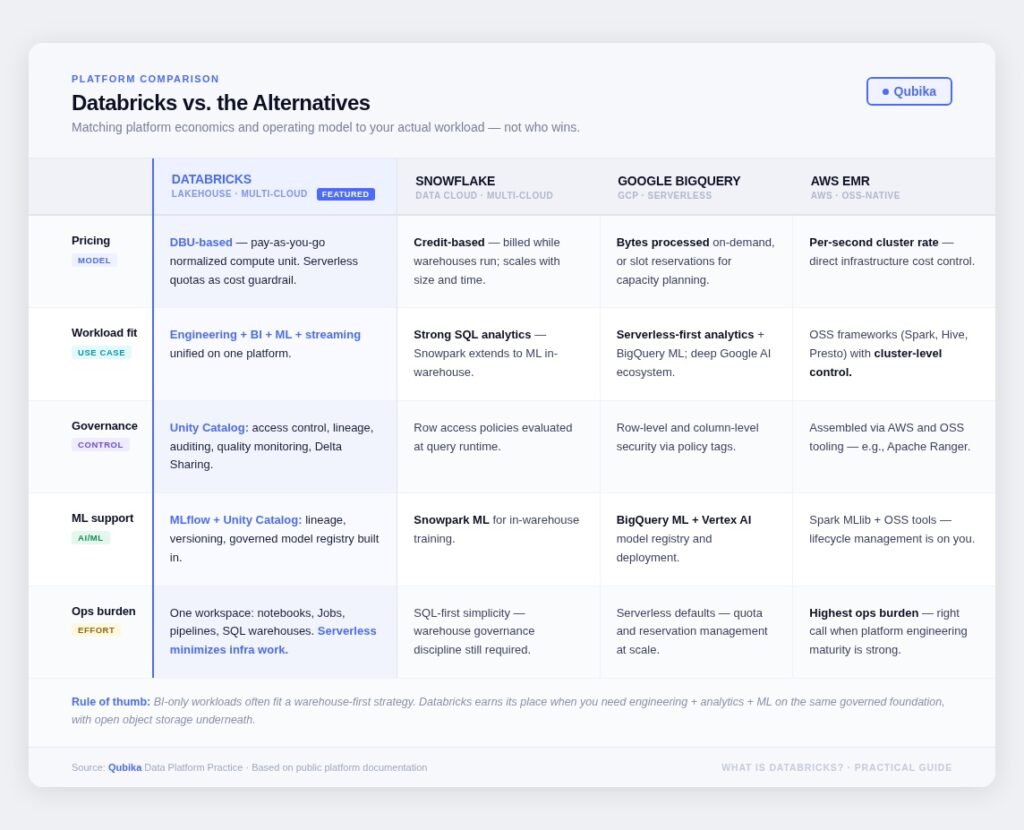
The rule of thumb I’ve landed on: if your primary workload is BI-only, a warehouse-first strategy often works well. Databricks earns its place when you need BI + engineering + ML on the same governed foundation, with the economics of open object storage underneath.
Best practices
Four things that actually matter
After reducing everything to what I’d tell a leadership team walking into an evaluation, these four come up in almost every engagement.
Start with Delta Lake discipline. Databricks’ official cost-optimization guidance explicitly calls out using Delta Lake as the storage framework from day one. It’s not a best practice, it’s the foundation everything else sits on.
Adopt Unity Catalog first — or pay the migration cost later. It’s far easier to build trust early than to retroactively repair governance. Treat Unity Catalog as infrastructure, not as a feature to be turned on when things stabilize.
Operationalize costs like a product. Use billing system tables. Build the three dashboards during the pilot, not after. If you answer “no” to cost discipline, the platform will scale your confusion faster than it scales your output.
Pin production workloads to LTS runtimes. Databricks documents explicit end-of-support dates for LTS releases. Establish a runtime upgrade cadence early, it’s a non-issue when planned, and a significant risk when not.
Decision framework
Five questions that actually decide this
You don’t need a 40-slide deck. You need honest answers to these. If most come back yes, Databricks is usually the right call. If governance and cost discipline come back no, no platform will fix the fundamentals, you’ll just scale confusion faster.
01 – Are we trying to unify engineering + analytics + ML on one governed foundation, rather than optimizing only for SQL BI?
02 – Do we have a clear data ownership model (domains, product owners, stewards) that Unity Catalog can enforce through access control and lineage?
03 – Can we commit to cost transparency: DBU-based measurement, system tables dashboards, and serverless quotas as guardrails from day one?
04 – Do our latency and concurrency requirements point toward serverless SQL warehouses, or do we need network customization via classic or Pro compute?
05 – Which cloud integrations matter most, AWS account isolation, Azure-native governance alignment, or GCP ecosystem integrations with BigQuery and Vertex AI?
Explore our Databricks services
Qubika is a Databricks Gold Partner with 200+ certified engineers across data, AI, and ML. Whether you're adopting Lakeflow, migrating existing pipelines, or designing a lakehouse from scratch, our team brings hands-on platform experience to every engagement.


