


















Lakebase: OLTP, Analytics and AI on One Platform
With Databricks Lakebase, transactional workloads are no longer a separate concern from analytics and AI. Lakebase brings a managed, serverless PostgreSQL engine directly into the Databricks Lakehouse, making OLTP a first-class citizen alongside Delta Lake, MLflow, and Databricks Apps.
At Qubika, we already explored the fundamentals of this shift in a previous post — Bringing OLTP into your Lakehouse: Why Databricks Lakebase is a game changer — where we dive deeper into what Lakebase is, why Databricks introduced it at the Databricks Data + AI Summit 2025, and how it reshapes transactional workloads on the Lakehouse.
This post builds on that foundation and focuses on one of the most compelling real-world fits of Lakebase in practice: enabling stateful AI agents without adding infrastructure, pipelines, or operational complexity.
Context: The Business Case Behind the Accelerator
Before diving into how Lakebase enables agent memory and why it became such a strong fit for our architecture, it’s important to set the context of the business problem we were solving.
At Qubika, we built the Databricks Setup Accelerator to help enterprises configure, migrate, and optimize Databricks environments at scale. Setting up Databricks correctly is not a trivial task: it involves governance decisions, Unity Catalog configuration, permission models, naming conventions, and CI/CD alignment — all of which are often manual, error-prone, and inconsistent across environments.

Our accelerator automates this process end to end by combining:
-
ERD and schema parsing
-
Governance and Unity Catalog policy enforcement
-
SQL generation for catalogs, schemas, tables, and permissions
-
Deployment through Databricks Apps and CI/CD pipelines
To make this work in real enterprise scenarios, the accelerator relies on an AI agent capable of handling long-running, multi-step workflows — not a stateless chatbot, but a system that needs to remember, reason, and resume.
AI Agents Need Persistent Memory — and Lakebase Is a Perfect Fit
For many years, building stateful AI applications meant juggling two separate infrastructure stacks. AI agents and LLMs lived in the analytics world of notebooks and pipelines, while the conversation history and user state they needed lived in external PostgreSQL databases, Redis caches, or document stores.
This split resulted in complex authentication flows, duplicated infrastructure, cross-network latency, and significant DevOps overhead.
Lakebase is a new category of operational database that bridges the long-standing division between transactional and analytical systems. By bringing online processing directly into the Databricks Lakehouse, teams can build interactive apps, dashboards, and AI agents on the same foundation as their analytics and models.
The Challenge: AI Agents Without Memory Are Stateless
When we started building the Databricks Setup Accelerator — an AI-powered tool that helps enterprises configure, migrate, and optimize their Databricks environments — we faced a fundamental challenge: AI agents need persistent memory.
Our accelerator uses LangGraph for intelligent workflow orchestration, and it needs to:
-
Remember conversation context across user sessions
-
Track workflow state for multi-step configuration tasks
-
Manage user isolation for multi-tenant enterprise deployments
-
Associate uploaded files with specific conversations
Without a proper OLTP backend, this would have required provisioning external PostgreSQL clusters, managing credentials, handling backups, and building custom integrations — all while maintaining millisecond-level response times for real-time interaction.
Lakebase removed that entire layer of complexity.
Why Lakebase Was the Right Choice
Lakebase fit our needs with zero architectural compromise:
-
PostgreSQL compatibility: Drop‑in replacement using SQLAlchemy and standard drivers
-
Serverless by default: No sizing, patching, or scaling decisions
-
Same‑workspace deployment: OLTP lives next to notebooks, models, and apps
-
Unity Catalog governance: Conversation data follows the same policies as analytics
-
Native OAuth authentication: No database passwords, no secrets to rotate
From an engineering perspective, this is the key shift: AI memory becomes just another governed asset in the Lakehouse.
Deep Dive: Agent Memory Architecture on Lakebase
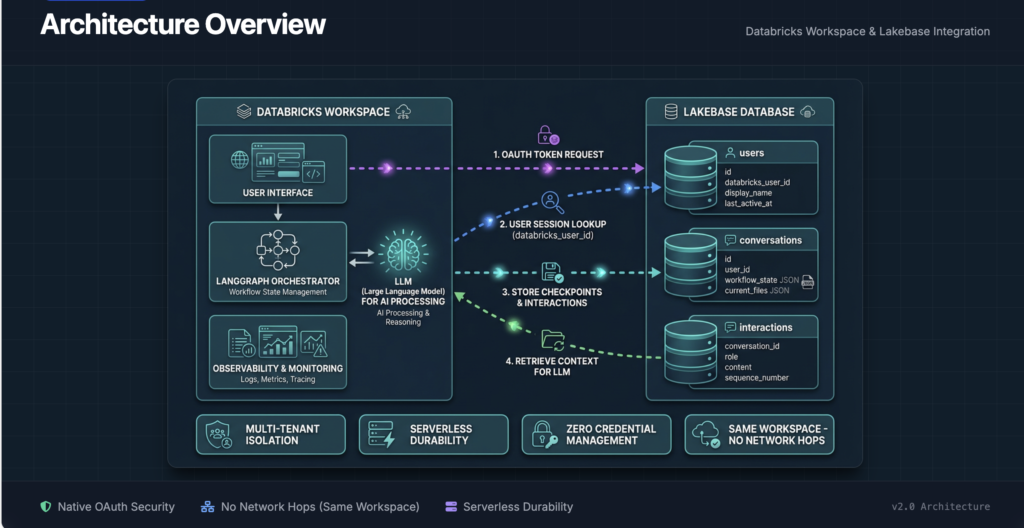
In the Databricks Setup Accelerator, Lakebase is responsible for three critical layers of memory:
1. User Management
Each Databricks user is mapped to an internal user record. Lakebase enables fast lookups and strict isolation in multi‑tenant setups.
-
User identity tied to Databricks authentication
-
Last activity tracking
-
No external IAM system required
2. Conversation & Workflow State
LangGraph checkpoints are stored as JSON in Lakebase tables. This allows users to pause and resume complex workflows without losing context.
-
Deterministic recovery of agent state
-
Support for long‑running, multi‑step tasks
-
No in‑memory hacks or fragile caches
3. Interaction History
Full conversation history is persisted with ordering and roles (user, assistant, system), enabling context‑aware responses and auditability.
This design gives us durable, queryable, governed AI memory — something that is extremely difficult to achieve with external databases.
Security & OAuth: A Quiet Game Changer
One of the most impactful (and underrated) features is Lakebase’s native OAuth integration.
Our Databricks App authenticates to Lakebase using the workspace’s OAuth token. No credentials are stored, no secrets are injected, and no passwords ever exist.
This single feature:
-
Removes an entire attack surface
-
Simplifies deployment pipelines
-
Aligns perfectly with enterprise security requirements
|
Before Lakebase |
After Lakebase |
|---|---|
|
External PostgreSQL cluster |
Same-workspace Lakebase instance |
|
Password rotation workflows |
Native OAuth authentication |
|
Separate monitoring stack |
Unified Databricks observability |
|
Manual backup configuration |
Serverless, automatic durability |
|
Cross-cloud networking |
No network hops required |
Final Thoughts: Lakebase as the Missing Layer for AI Agents
Lakebase is not just “PostgreSQL inside Databricks”. For AI workloads, it is the missing memory layer that finally makes production‑grade agents viable on the Lakehouse.
For Qubika’s Databricks Setup Accelerator, Lakebase enabled something fundamental: AI agents that remember, reason, and evolve — without adding infrastructure complexity.
If you’re building AI agents, interactive applications, or real‑time systems on Databricks, Lakebase is the foundation that lets you do it right.
“Lakebase was the missing piece for building production AI agents on Databricks. Our accelerator needs persistent memory across sessions and workflows. With Lakebase, we achieved native PostgreSQL OLTP with zero operational overhead.”
— Facundo Sentena, Sr. AI Engineer, Qubika


