

















1. The Vision & Architecture
The Setting
Football data is fragmented, deeply nested, and rate-limited. The football-data.org API exposes match results, standings, team rosters, and scorer statistics across dozens of competitions — but it does so as raw JSON with nested objects, composite keys, and a strict 10-requests-per-minute throttle on its free tier. Turning that into clean, queryable, analyst-ready tables requires more than a script and a cron job. It requires a platform.
This project solves that problem by building a fully governed Data Lakehouse on Databricks, designed to ingest all TIER_ONE competition data daily, enforce schema and quality at every layer, and expose standardized tables ready for dashboards, BI tools, and future ML models.
The Architecture in Prose
The platform follows the Medallion Architecture — a layered data design pattern that separates concerns across three tiers:
football-data.org API (v4)
│
▼
┌───────────────┐
│ RAW LAYER │ 7 notebooks fetch, flatten, and land API responses
└───────┬───────┘
▼
┌───────────────┐
│ BRONZE LAYER │ 1 parameterized template enforces schemas and deduplicates
└───────┬───────┘
▼
┌───────────────┐
│ SILVER LAYER │ 1 template + 6 SQL transforms standardize and enrich
└───────┬───────┘
▼
┌───────────────┐
│ GOLD LAYER │ (Planned) Star schema: fact_matches, dim_teams, dim_leagues
└───────────────┘Every table lives as a Delta Lake managed table inside Unity Catalog (qubika_partner_solutions.sports_data), which means storage paths, access control, and column-level lineage are handled transparently — no mount points, no S3 path management, no manual ACLs.
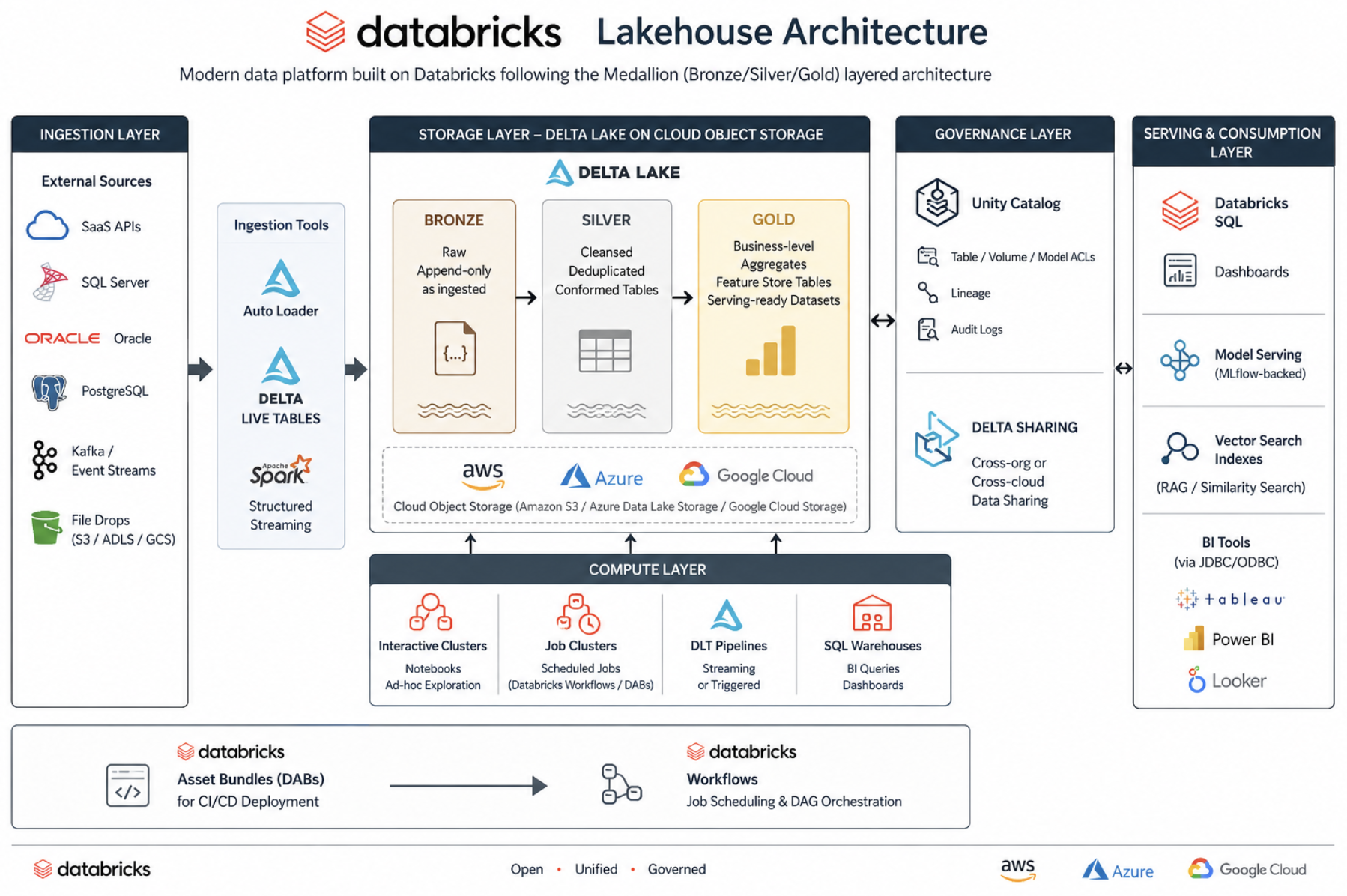
2. The Engineering Engine
Ingestion: A Purpose-Built API Client
At the heart of the Raw layer sits FootballAPIClient (lib/football_api/client.py) — a Python class that encapsulates all HTTP communication with the football-data.org – ur src for machine readable football data API.
Why not just callrequests.get() directly in each notebook? Because the API’s free tier only allows 10 requests per minute — and our pipeline makes hundreds of calls per run. Without a centralized client, every notebook would need its own retry logic, its own rate-limit handling, and its own error management. That’s seven places to get it wrong.
The custom client solves this in one place:
-
It waits automatically. A built-in 6-second pause between requests keeps us under the rate limit without any notebook needing to think about it.
-
It retries on failure. If the API says “slow down” (HTTP 429) or has a server error (5xx), the client backs off and tries again — up to 3 times. No silent failures, no missing data.
-
It reuses connections. One persistent session handles authentication and connection pooling, so we’re not opening a new HTTP connection for every single call.
Seven dedicated notebooks in raw/ each call this client for a specific domain — areas, competitions, teams, matches, standings, scorers, and persons. Each notebook flattens nested JSON into tabular rows, stamps them with ingestion_timestamp and source_endpoint metadata, and writes them to Unity Catalog. API keys never touch code; they’re stored in Databricks Secrets (scope: samueltavares_wc) and retrieved at runtime via dbutils.secrets.get().
The filtering strategy is deliberate: only TIER_ONE competitions (Premier League, Bundesliga, La Liga, Serie A, Ligue 1, Champions League, and others) are ingested. This focuses the platform on high-value data while respecting API rate limits.
Bronze Layer: Schema Enforcement Through a Single Template
Rather than writing seven nearly identical notebooks, the Bronze layer uses a single parameterized template (bronze/template.py). Databricks Workflows pass table-specific parameters — target table name, ID field, write mode — via base_parameters in the job JSON:
{
"table_target": "bronze_areas",
"id_field": "area_id",
"mode": "overwrite"
}The template reads the existing table, validates row counts, checks for null IDs and duplicates, then runs VACUUM to clean up old Delta file versions. Schemas are enforced at write time using PySpark StructType definitions from lib/football_api/schemas.py, which serve as the runtime source of truth. A parallel set of JSON schema files in bronze/football/schemas/ provides documentation for non-Spark tooling and CI validation.
Why overwrite instead of merge? The API returns complete datasets on every call — there’s no date-range filter or change feed. A full overwrite is idempotent, simpler to reason about, and eliminates the risk of CDC drift. If the API adds incremental endpoints in the future, the template already supports a merge mode.
Silver Layer: SQL Transforms with Governed Naming
The Silver layer follows the same single-template pattern (silver/template.py), but the transformation logic lives in standalone SQL files under silver/football/etl/. This separation is intentional: SQL is easier to review, test, and version than embedded strings in Python notebooks.
Each SQL file applies a strict column naming convention:
|
Prefix |
Meaning |
Example |
|---|---|---|
|
|
Identifier / Foreign Key |
|
|
|
Date or Timestamp |
|
|
|
Descriptive Text |
|
|
|
Boolean Flag |
|
|
|
Numeric Value |
|
This convention eliminates ambiguity. When an analyst sees vl_goals_per_match, they know it’s a computed numeric. When they see fl_draw, they know it’s a boolean. No documentation lookup required.
Storage & Governance: Unity Catalog + Delta Lake
Every table is a Unity Catalog managed table. This was a deliberate choice over DBFS mount points or explicit S3 paths:
-
No path management. Unity Catalog decides where files live. No
data_paths.json, no mount configurations, no risk of path collision. -
Integrated RBAC. Permissions are managed at catalog, schema, and table level — not at the filesystem layer.
-
Automatic lineage. Unity Catalog tracks which tables feed which downstream tables, column by column.
-
Delta Lake features for free. ACID transactions, schema evolution (
overwriteSchema: true), time travel for auditing, and VACUUM for storage cleanup — all enabled by default.
Compute: Cost-Optimized Job Clusters
The pipeline runs on job clusters — ephemeral Spark clusters that spin up for each workflow run and terminate immediately after so we do not have any idle compute costs. No over-provisioned clusters. The configuration matches the workload: a few thousand rows per table, seven tables, running once daily.
3. Operational Excellence
CI/CD: Two-Pipeline Automation
The project runs two GitHub Actions workflows:
1. Unit Tests (.github/workflows/test.yml) — Triggered on every PR and push to main. Runs pytest against three test suites:
-
test_client.py— Validates retry logic, rate limiting, and response parsing with mocked HTTP (11 test methods) -
test_schemas.py— Ensures JSON schema files and PySpark StructTypes are consistent and well-formed -
test_json_jobs.py— Validates job JSON syntax, task dependencies, and schedule expressions
All tests run without Spark — pure Python with <marj and pytest. CI feedback in seconds, not minutes.
2. Job Deployment (.github/workflows/deploy_jobs.yml) — Triggered on push to main when files under jobs/prod/ or jobs/scripts/ change. The pipeline:
-
Validates all job JSONs via
jobs/scripts/test_json.py -
Deploys to Databricks via
jobs/scripts/update_jobs.py, which calls the Jobs REST API to create or update each job
The deployment script handles orchestrator jobs specially: it deploys regular jobs (raw, bronze, silver) first, refreshes the job list, then deploys the master orchestrator — because main_football.json references child jobs by name, which must be resolved to job_id at deployment time.
Observability: Quality Gates at Every Layer
Data quality isn’t an afterthought — it’s built into the pipeline:
|
Layer |
Check |
Mechanism |
|---|---|---|
|
Bronze |
Null IDs, duplicates, row counts |
|
|
Silver |
Volume comparison, duplicates, nulls, freshness |
|
|
CI |
Schema consistency, job dependency graphs |
|
The Silver quality framework (quality_tests.py) runs three checks when quality_test=yes:
-
Volume: Does the silver table have a reasonable row count compared to its bronze source?
-
Duplicates: Are ID fields unique?
-
Nulls: Are primary keys populated?
Results are logged to notebook output, captured in Databricks job run history, and accessible through the Workflows UI. External alerting (Slack webhooks, email) is architecturally supported but not yet wired in.
Orchestration: Declarative Job Chaining
The master job (main_football.json) chains three child jobs using run_job_task:
main_football
├─ run_raw_football → 7 tasks, ~30-60 min
├─ run_bronze_football → 7 tasks, ~05-10 min (waits for raw)
└─ run_silver_football → 6 tasks, ~05-07 min (waits for bronze)Each child job defines its own task dependency graph. In the raw job, for example, ingest_persons depends on both ingest_scorers and ingest_matches because it enriches player and referee IDs extracted from those upstream tables. Timeouts are explicit: 30 minutes per regular task, 2 hours for the persons enrichment (which makes hundreds of individual API calls), and 4 hours per child job at the orchestrator level.
Git-Native Execution
Every notebook runs directly from Git at execution time:
"git_source": {
"git_url": "https://github.com/thisisqubika/World-Cup-Article",
"git_provider": "gitHub",
"git_branch": "main"
}The git_source pattern means no notebook upload, no workspace sync. This is actually a big deal for teams coming from DBFS-based pipelines. Worth a sentence explaining why: “This means every execution traces back to a specific git commit. Rollback is git revert. Debugging is git blame. No wondering which notebook version ran last night.
4. The Insights Layer
On top of the extracted data, we built an analysis considering numbers from the 2025/2026 season for the most relevant European football league tournaments: the English, Spanish, Italian, German, French, Dutch and Portuguese national competitions; and taking into consideration only players called by their national teams for the 2026 FIFA Men’s World Cup.
Player Availability by Nation
Considering the top 10 nations with the most active players in the analyzed leagues, the table below shows the average number of matches played per player. While it is no surprise that all countries whose leagues are featured appear in the top 10 (excluding Italy, which failed to qualify), some unexpected nations also appear, like Austria, Belgium, Senegal and Croatia, none of whom have yet won a World Cup title. A curious footnote: the league with the highest average matches played by World Cup-bound players is Serie A — whose own national team didn’t make it.
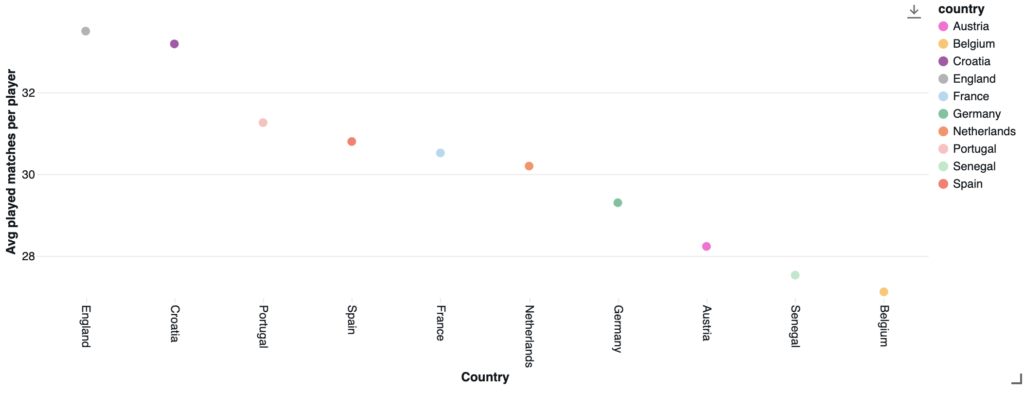
Interestingly, among the leagues analyzed, the one with the highest average number of matches played by World Cup-bound players is the Italian league, whose national team failed to qualify.
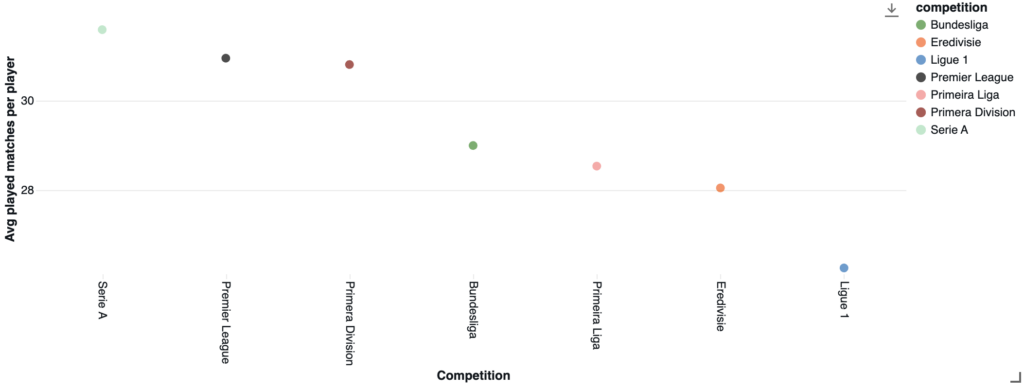
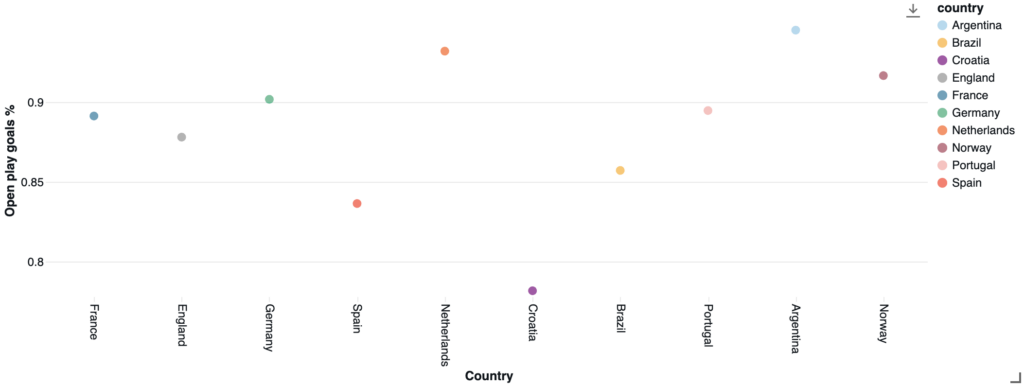
Goals: Open Play vs. Penalties
Considering the 10 countries with the most goals scored by their players in the analyzed leagues, France leads in absolute terms, followed by other host nations. Traditional powerhouses Brazil and Argentina, along with Croatia and Norway (home to world-class striker Haaland) complete the list.
The Netherlands and Argentina score almost entirely through open play (93–94%), meaning they build chances organically rather than relying on set pieces or penalties. Croatia does the opposite: nearly a quarter of their goals come from the spot, signaling a team that leans on drawing fouls to manufacture opportunities.
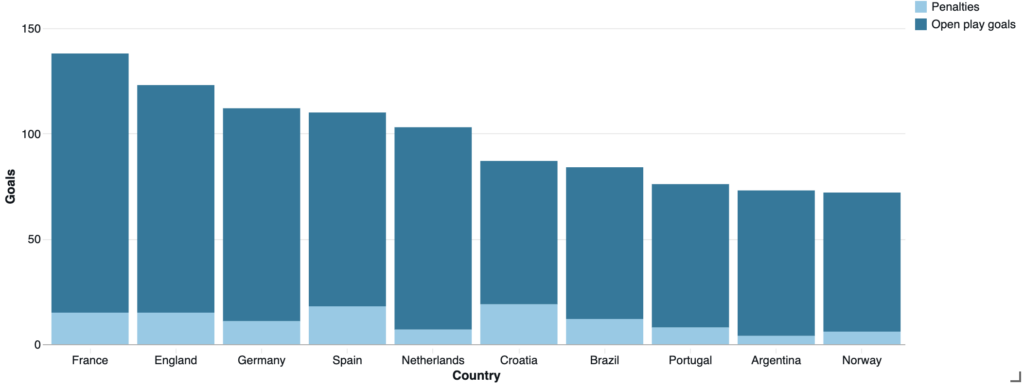
When replicating the same calculations at the league level, the English league leads in total values, followed by the German and Spanish championships. However, the leagues with the highest percentage of open-play goals are the Dutch (Eredivisie), French (Ligue 1), and Italian (Serie A) leagues.
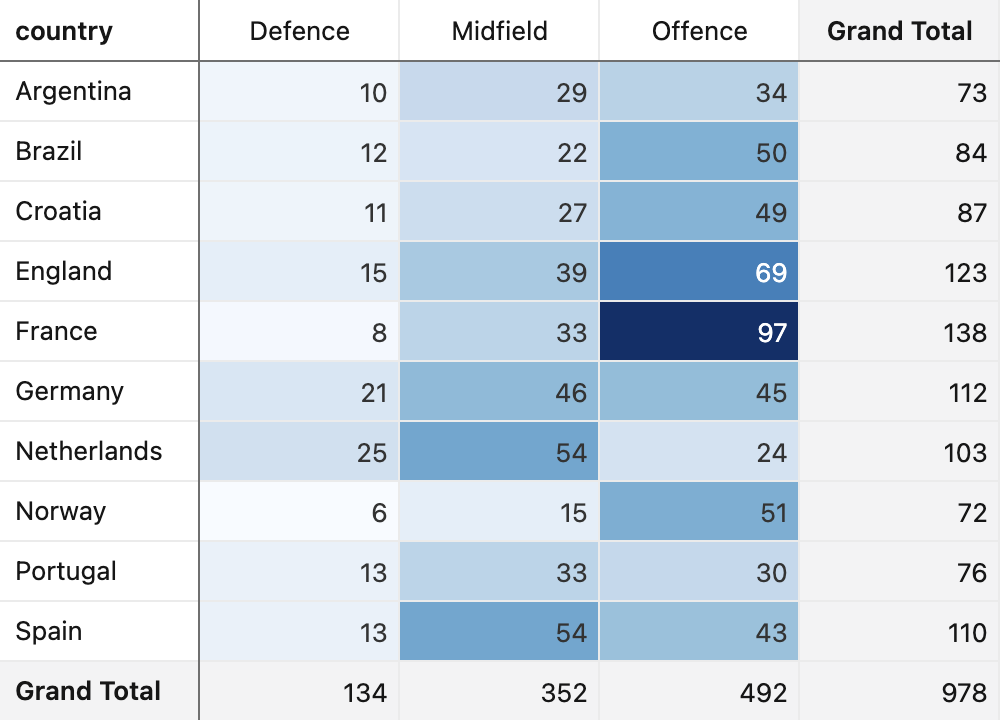
Goals by Field Position
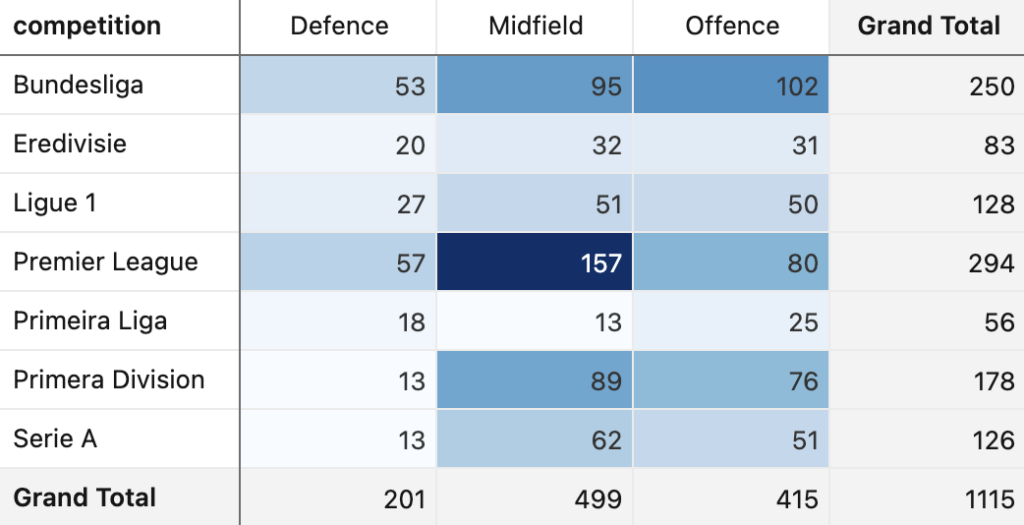
Considering which areas of the field the goals of the top-scoring teams came from, some interesting patterns emerge where the expected logic is subverted: more goals originate from midfielders than from forwards for the Netherlands, Spain, Portugal, and Germany (the latter has almost equal numbers between midfielders and forwards). France and Norway have the largest discrepancies between goals from forwards compared to other positions. One particularly curious fact: Dutch defenders scored more goals than their own forwards in the leagues analyzed.
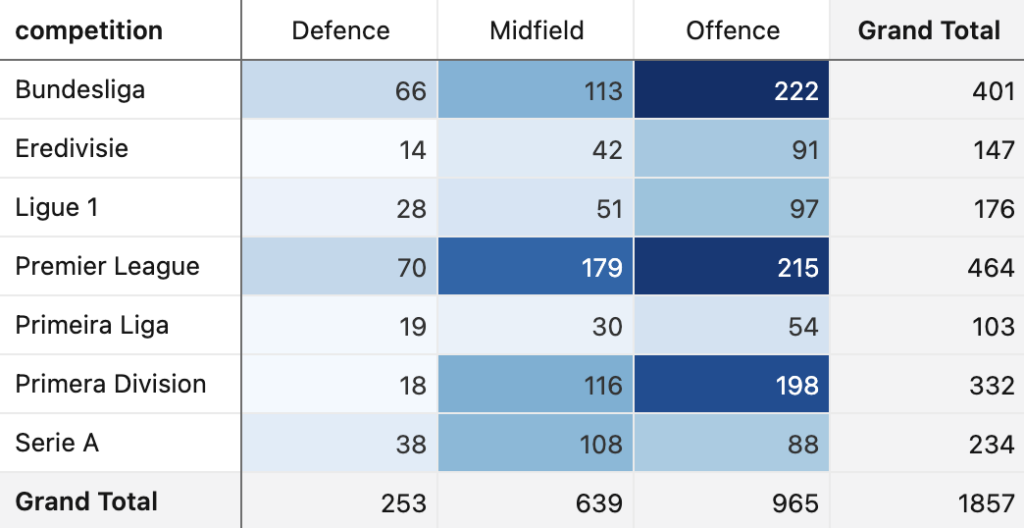
At the league level, the German Bundesliga has lethal forwards leading its scorers, the English and Spanish leagues show balanced scoring contributions across attack and midfield, and the Italian Serie A will have many prolific midfielders representing it at this World Cup.
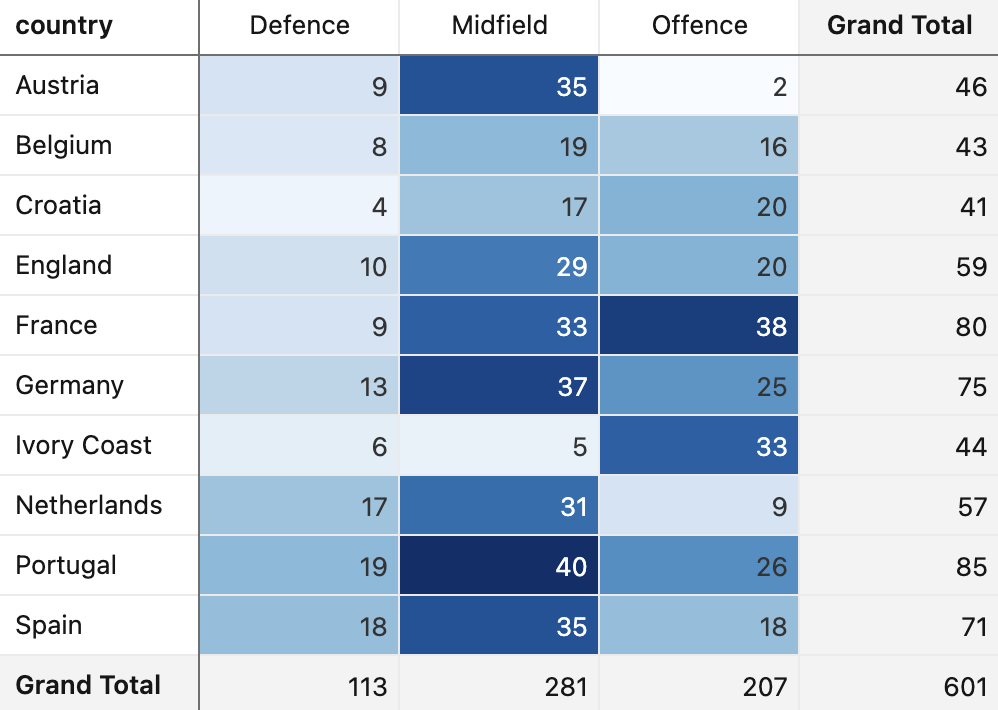
Assists by Field Position
Among the top 10 nations with the most recorded assists in the last season across the analyzed leagues, we find the league host nations who qualified for the World Cup, as well as familiar faces from other metrics — Austria, Belgium, and Croatia — plus one new entrant: Ivory Coast.
The assists data reveals an interesting diversity of playing styles: most countries maintain a balanced proportion between assists from midfielders and forwards, but there are notable extremes. For Austria, the vast majority of goal-creating passes came from midfield. For Ivory Coast, the attack is the primary source of assists. Spain stands out for its versatility: equal numbers of assists recorded between defenders and forwards, with an even higher total from midfield.
Finally, looking at how each of the leagues analyzed will be represented in terms of assists, it’s clear that the English and Spanish leagues will have many midfielders who create goal-scoring opportunities in this World Cup, as well as good, supportive forwards. However, the league that will provide forwards with the most assists this season will be the German league.
Based on the data we analyzed, we were able to identify patterns that will make our way of watching the World Cup games more attentive to details that are not so easily perceived: from the scoring defense of the Netherlands and the unpredictability of the Dutch offensive actions, to the tactical application of the Croatians, the insights promise an astonishing competition.
Build yourself
If you want to start building your own football analytics platform using Databricks, we’ve got you covered. We have shared the boilerplate ingestion script in our GitHub repository: football-databricks-data.
All you need to get up and running is a Databricks workspace and a Football API key. Clone the repo, spin up your notebook, and start uncovering deep sports insights and match predictions today!


